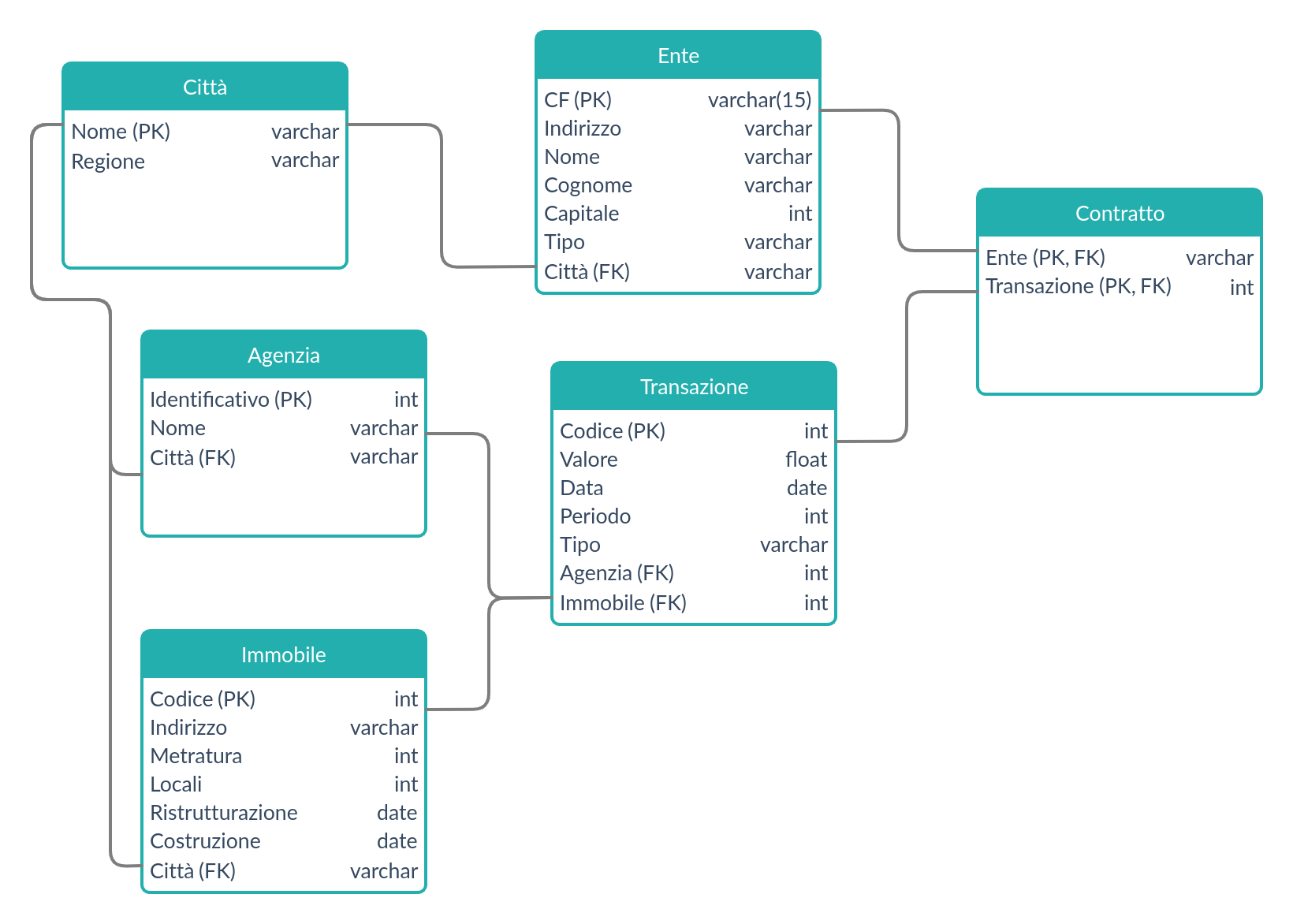
Basi di Dati
Andrea De Lorenzo, University of Trieste
Orario lezioni
| Giorno | Orario | Aula |
|---|---|---|
| Lunedì | 16:10 - 18:40 | Aula A C2 |
| Martedì | 14:15 - 16:45 | Aula A C9 |
| Mercoledì | 9:30 - 11:00 | Aula 2 C5 |
Modalità esame
Progetto + Orale
Progetto va consegnato 3 giorni lavorativi prima dell’appello Se l’esame è mercoledì, venerdì è troppo tardi per inviare il progetto!
Gestione delle informazioni
L’essere umano genera e gestisce tante informazioni:
- idee informali
- linguaggio naturale (scritto o parlato, in lingue diverse)
- disegni, grafici, schemi
- numeri
- codici
Gestione delle informazioni
... salvate in tanti modi diversi
- memoria
- carta
- pietra
- scritta sul muro
- elettronica
Gestione delle informazioni
Anche le organizzazioni generano informazioni:
- utenze telefoniche
- conti correnti
- studenti iscritti ad un corso di laurea
- quotazioni di azioni
Codifica delle informazioni
Era informatica
Le informazioni vanno codificate
- si aggiungono elementi artificiali
- primo esempio: anagrafe
- nome e cognome
- indirizzo
- codice fiscale
Informazione vs Dato
Informazione: notizia, dato o elemento che consente di avere conoscenza più o meno esatta di fatti, situazioni, modi di essere
Dato: elemento di informazione costituito da simboli che debbono essere elaborati
Cartelli stradali in Finlandia

Lun - Ven
Sabato

Festivi
Numeri
Come codifico i numeri?
- Numeri naturali: facile, in binario
- Numeri interi: devo decidere come rappresentare il segno
- Numeri razionali?
10010011110011001111
Dati e Applicazioni
- I dati possono variare nel tempo (es: conto corrente)
- Le modalità con cui i dati sono rappresentati sono di solito stabili
- Le operazioni sui dati variano spesso (es: ricerche)
separare i dati dalle applicazioni che operano su essi
Data Base
Genericamente:
Collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni di una organizzazione.
- schede perforate
- file CSV
- foglio di calcolo
- file XML
- Access
DataBase Management System
Software in grado di gestire collezioni di dati che siano:
- grandi: di dimensioni (molto) maggiori della memoria centrale
- persistenti: con un periodo di vita indipendente dalla singole esecuzioni dei programmi che le utilizzano
- condivise: utilizzate da applicazioni diverse
Base di Dati
Genericamente
Collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni di una organizzazione
Per noi
Collezione di dati gestita da un DBMS
DataBase managment System
Un DBMS deve garantire:
- affidabilità: resistenza a malfunzionamenti hardware e software
- privatezza: con una disciplina e un controllo degli accessi
- efficienza: utilizzando al meglio le risorse di spazio e etempo del sistema
- efficacia: rendendo produttive le attività dei suoi utilizzatori
Condivisione
- più dipartimenti sono interessati agli stessi dati
- una base di dati è una risorsa integrata, condivisa
Condivisione
- L’integrazione e la condivisione permettono di
- ridurre la ridondanza (evitando ripetizioni)
- ridurre possibilità di incoerenza (o inconsistenza) fra i dati.
- Poiché la condivisione non è mai completa (o comunque non opportuna) i DBMS prevedono meccanismi per
- privatezza dei dati
- limitazione all’accesso (autorizzazioni).
- La condivisione richiede coordinamento degli accessi: controllo della concorrenza.
Efficienza
- Si misura in termini di tempo di esecuzione e spazio di memoria (principale e secondaria)
- I DBMS non sono necessariamente più efficienti dei file system
- L’efficienza è il risultato della qualità del DBMS e delle applicazioni che lo utilizzano
DBMS vs FS
| FS | DBMS | |
|---|---|---|
| Grandi moli di dati | ✓ | ✓ |
| Persistenti | ✓ | ✓ |
| Condivisi | ✓ | ✓ |
| Affidabile | ✓ | ✓ |
| Privatezza | ✓ | ✓ |
| Efficienza | ? | ? |
| Efficacia | X | ✓ |
File System
Descrizione dei dati contenuta nell'applicazione
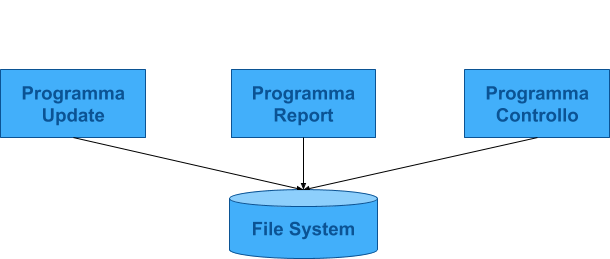
File System
Descrizione dei dati contenuta nell'applicazione
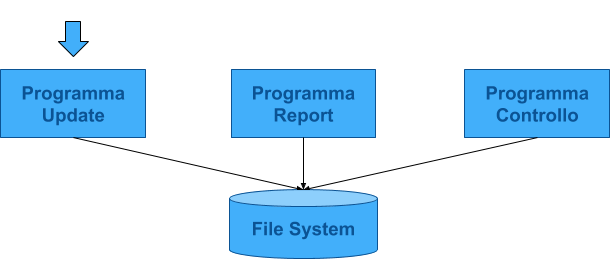
File System
Descrizione dei dati contenuta nell'applicazione
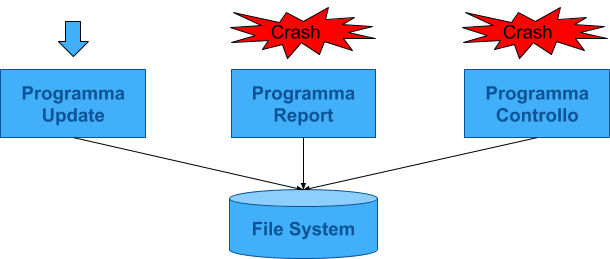
DBMS e Descrizione dei Dati
- Il DBMS sa come persistere i dati, per l’applicazione è un atto di fede
- I dati sono INDIPENDENTI dalla forma fisica
- I programmi parlano con il DBMS per accedere ai dati
Modello Concettuale
Analisi del problema
Modello astratto
Non dipende dallo strumento utilizzato
Modello Logico
Come rappresentare i dati individuati con il modello concettuale
- Livello intermedio tra utente e implementazione
- sottintende una specifica rappresentazione dei dati (tabelle, alberi, grafi, oggetti, …)
DataBase System
- Software
- DBMS: interposto tra il DB e l’utente
- Utility di supporto (sviluppo, backup)
- Utenti
- Progettista
- Sviluppatore
- Amministratore
- Utente finale
DataBase System
- Schemi (struttura dei dati)
- Dati
- come vengono salvati
- condivisione
- concorrenza
- ridondanza
- Hardware
Base di Dati
- Genericamente: collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni di una organizzazione.
- Per noi: collezione di dati gestita da un DBMS
- Per noi - 2: collezione di dati persistenti usata dal sistema di una azienda e gestita da un DBMS
Riassunto
- Data base
- Dati, solo dati, niente altro che i dati
- Data Base Managmnet System
- Software che gestisce i dati
- Diversi vendor: IBM, Oracle, Microsoft
- Data Base System
- DB + DBMS
Vantaggi e Svantaggi
- Vantaggi
- Dati sono risorsa in comune
- DB fornisce un modello unificato del business
- Controllo centralizzato dei dati, quindi standardizzazione ed economie di scala
- Riduzione ridondanza ed inconsistenza
- Indipendenza dei dati
- Svantaggi
- Costo e complessità
- Servizi ridondanti/non necessari
Vero beneficio
Indipendenza dei dati!
Vero beneficio
Nei vecchi sistemi il modo in cui venivano organizzati i dati e le tecniche per accedervi facevano parte della logica e del codice del programma.
Schema ed Istanza
In ogni base di dati esistono:
- Schema:
- invariante nel tempo
- descrive la struttura
- es: intestazione tabelle
- Istanza:
- i valori attuali
- possono cambiare
- es: contenuto delle tabelle
Schemi
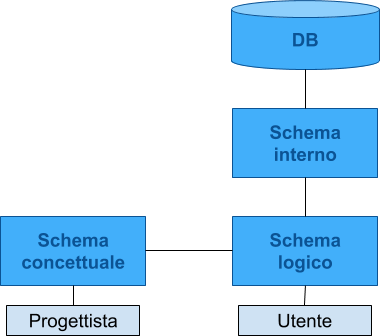
Schemi concettuali
Permettono di rappresentare i dati in modo indipendente da ogni sistema:
- cercando di descrivere i concetti del mondo reale
- sono utilizzati nelle fasi preliminare di progettazione
Modello più diffuso: Entity-Relationship
Schermi interni (o fisici)
Rappresentazione dello schema logico per mezzo di strutture di memorizzazione
- file CSV
- file XML
- file binari
Schemi logici
Come è organizzato il DB. Diverse soluzioni:
- gerarchico
- reticolare
- relazionale
- ad oggetti
Indipendenza
Lo schema logico è INDIPENDENTE da quello fisico
Es: una tabella è utilizzata sempre allo stesso modo qualunque sia la sua realizzazione fisica (che può variare nel tempo)
Indipendenza
Progettista DB ≠ Sviluppatore SW
Vista
L'amministratore del DB può modificare la struttura interna dei dati senza toccarne la visibilità esterna
IMMUNITÀ DELLE APPLICAZIONI A MODIFICHE DI STRUTTURA
Vista
| Corso | Docente | Aula |
|---|---|---|
| Reti | Bartoli | N3 |
| Programmazione | Medvet | N3 |
| ML | Medvet | G |
| Nome | Edificio | Piano |
|---|---|---|
| DS1 | H3 | 3 |
| N3 | C2 | 2 |
| G | Principale | PT |
| Corso | Docente | Aula | Edificio | Piano |
|---|---|---|---|---|
| Reti | Bartoli | N3 | C2 | 2 |
| Programmazione | Medvet | N3 | C2 | 2 |
| ML | Medvet | G | Principale | PT |
Vista
| Nome | Cognome | Matricola | Media | ISEE |
|---|---|---|---|---|
| Tizio | Caio | IN0001 | 30 | 5000€ |
| Bubba | Gump | IN0003 | 27 | 1000000e |
| Jean Luc | Picard | IN0004 | 19 | 40000€ |
| Nome | Cognome | Matricola | ISEE |
|---|---|---|---|
| Tizio | Caio | IN0001 | 5000€ |
| Bubba | Gump | IN0003 | 1000000e |
| Jean Luc | Picard | IN0004 | 40000€ |
| Nome | Cognome | Matricola | Media |
|---|---|---|---|
| Tizio | Caio | IN0001 | 30 |
| Bubba | Gump | IN0003 | 27 |
| Jean Luc | Picard | IN0004 | 19 |
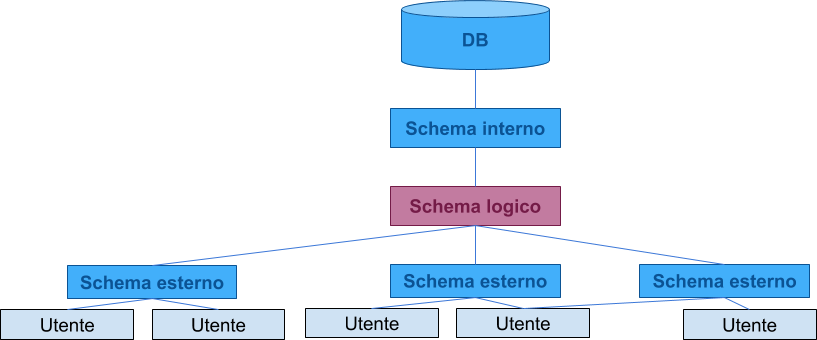
Schema Esterno
== VISTA
- Descrive parte della base di dati di un modello logico
- NON è una copia dei dati
Architettura ANSi/SPARC
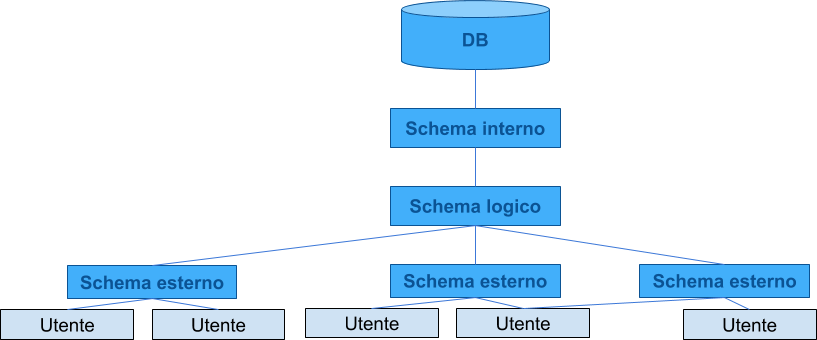
Schemi Logici
Schemi Logici Gerarchici
Schemi Logici Gerarchici
Problemi:
- accesso sequenziale: per arrivare al figlio devo attraversare tutti i nodi
- modifica parziale complicata
- cancellazione gerarchica
- stretto legame tra programma e struttura del database
- ridondanza
Schemi Logici Gerarchici (Ridondanza)

Schemi Logici Reticolari
- COBOL, 1970
- nodi collegati da PUNTATORI
- navigazione bi-direzionale
Schemi Logici Reticolari
Schemi Logici Relazionali
Codd, 1980
Liberarsi dei puntatori fisici
- i dati sono organizzati in tabelle di valori
- le operazioni vengono eseguite sulle tabelle
- i risultati delle operazioni sono tabelle
- i riferimenti tra dati in strutture (tabelle) diverse sono rappresentati con valori
Elementi di un DBR
Tabelle: organizzazione rettangolare di dati
- Record (righe) e campi (colonne) e domini dei dati
- I campi definiscono univocamente il tipo dei dati (dominio)
- I campi hanno un nome ed un ordine, le righe no
- Esistono tabelle vuote
Elementi di un DBR
Chiavi primarie
- Una (o più) colonne che identificano UNIVOCAMENTE il record
- Non possono essere duplicate
- Una tabella in cui ogni riga è diversa dalle altre è detta RELAZIONE
Elementi di un DBR
Relazioni
- Non esistono relazioni padre-figlio
- Le relazioni sono rappresentate da DATI COMUNI manipolabili
Chiavi Esterne (Secondarie, Foreign Key)
- Una colonna in una tabella il cui valore corrisponde ad una chiave primaria
- Sono fondamentali nella creazione delle relazioni
Dodici regole di Codd
Dodici regole di Codd
1 - Informazioni
Tutte le informazioni in un DBR sono rappresentate esplicitamente da valori in tabelle (DEFINIZIONE)
Dodici regole di Codd
2 - ACCESSO GARANTITO
Ciascun valore deve essere raggiunto univocamente da un nome di tabella, chiave primaria e nome di colonna (CHIAVI PRIMARIE)
Dodici regole di Codd
3 - VALORI NULL
Sono supportati per rappresentare informazioni mancanti indipendentemente dal tipo di dato
Dodici regole di Codd
4 - SYSTEM TABLE
Un data base relazionale deve essere strutturato logicamente come i dati e gestibile con lo stesso linguaggio
Dodici regole di Codd
5 - LINGUAGGIO DI INTERROGAZIONE STANDARD
Un DBR può supportare diversi linguaggi, ma deve supportare un linguaggio “English like” dove sia possibile (DEFINIZIONE DI SQL):
- Definire dati
- Definire viste
- Manipolare dati
- Gestire l’integrità
Dodici regole di Codd
6 - VISTE MODIFICABILI
Le viste che sono modificabili teoricamente dall’utente lo devono essere anche dal sistema (cruciale per campi calcolati);
Dodici regole di Codd
6 - VISTE MODIFICABILI
Affinché una vista sia modificabile, il DBMS deve essere in grado di tracciare ciascuna colonna e ciascuna riga UNIVOCAMENTE fino alle tabelle origine
Viste Modificabili
| Corso | Docente | Aula |
|---|---|---|
| Reti | Bartoli | N3 |
| Programmazione | Medvet | N3 |
| ML | Medvet | G |
| Nome | Edificio | Piano |
|---|---|---|
| DS1 | H3 | 3 |
| N3 | C2 | 2 |
| G | Principale | PT |
| Corso | Docente | Aula | Edificio | Piano |
|---|---|---|---|---|
| Reti | Bartoli | N3 | C2 | 2 |
| Programmazione | Medvet | N3 | C2 | 2 |
| ML | Medvet | G | Principale | PT |
Viste Modificabili
| Studente | Esame | Voto |
|---|---|---|
| Scaini | Reti | 30 |
| Scaini | ML | 28 |
| Bassi | ML | 30 |
| Bassi | Reti | 30 |
| Studente | Media |
|---|---|
| Scaini | 29 |
| Bassi | 30 |
Dodici regole di Codd
7 - INSERIMENTO E UPDATE DA LINGUAGGIO
Inserire e aggiornare devono avere la stessa logica “a righe” dell’estrazione (SET ORIENTED)
Dodici regole di Codd
8 - INDIPENDENZA FISICA DEI DATI
I programmi applicativi non devono sentire alcuna modifica fatta sul metodo e la locazione fisica dei dati
Dodici regole di Codd
9 - INDIPENDENZA LOGICA DEI DATI
Le modifiche al livello logico non devono richiedere cambiamenti non giustificati alle applicazioni che utilizzano il database (VISTE)
Dodici regole di Codd
10 - INTEGRITÀ
Vincoli di integrità devono essere implementabili sul motore (cruciale)
Dodici regole di Codd
11 - INDIPENDENZA DI LOCALIZZAZIONE
La distribuzione di porzioni del database su una o più allocazione fisiche o geografiche deve essere invisibile agli utenti del sistema
Dodici regole di Codd
12 - DEVE PREVENIRE ACCESSI NON DESIDERATI:
Garantisce l’impossibilità di bypassare le regole di integrità
Riassunto: DB Relazionale
Data Base dove tutti i dati visibili all’utente sono organizzati strettamente in tabelle di valori, e dove tutte le operazioni vengono eseguite su tabelle e danno come risultato tabelle.
Relazione
Relation
Relazione matematica (teoria degli insiemi)
Relationship
Associazione nel modello Entity-Relationship
Relazione Matematica
- $D_1, \dots, D_n$ ($n$ insiemi anche distinti) sono i domini
- prodotto cartesiano $D_1 \times \dots \times D_n$
- insieme di tutte le $n$-uple ($d_1, \dots, d_n$) tali che $d_1 \in D_1, \dots, d_n \in D_n$
- relazione matematica su $D_1, \dots, D_n$:
- un sottoinsieme di $D_1 \times \dots \times D_n$
Relazione Matematica (esempio)
| a | x |
| a | y |
| a | z |
| b | x |
| b | y |
| b | z |
Relazione Matematica (esempio)
| a | x |
| a | z |
| b | y |
Relazione Matematica (proprietà)
- una relazione matematica è un insieme di $n$-uple ordinate:
- $ (d_1, \dots, d_n ) \mid d_1 \in D_1, \dots, d_n \in D_n $
- una relazione è un insieme:
- non c’è ordinamento tra le $n$-uple
- le $n$-uple sono distinte
- ogni $n$-upla è ordinata: $i$-esimo valore proviene dall’$i$-esimo dominio
Relazione Matematica (esempio)
| Juve | Lazio | 3 | 1 |
| Lazio | Milan | 2 | 0 |
| Juve | Roma | 2 | 0 |
| Roma | Milan | 0 | 1 |
- ciascuno dei domini ha due ruoli diversi, distinguibili attraverso la posizione
- la struttura è posizionale
Struttura NON Posizionale
A ciascun dominio si associa un nome (attributo), che ne descrive il "ruolo"
| Casa | Fuori | RetiCasa | RetiFuori |
|---|---|---|---|
| Juve | Lazio | 3 | 1 |
| Lazio | Milan | 2 | 0 |
| Juve | Roma | 2 | 0 |
| Roma | Milan | 0 | 1 |
Tabelle e Relazioni
- Una tabella è una relazione se:
- i valori di ogni colonna sono omogenei
- le righe sono diverse fra di loro
- le intestazioni delle colonne sono diverse tra di loro
- In una tabella che rappresenta una relazione:
- l’ordinamento tra le righe è irrilevante
- l’ordinamento tra le colonne è irrilevante
Relazione
- Relation: relazione matematica (teoria degli insiemi)
- Relationship: rappresenta una associazione nel modello Entity-Relationship
Prima
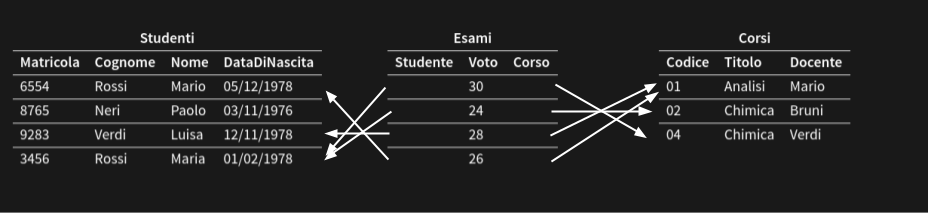
Modello basato su VALORI
I riferimento fra dati in relazioni diverse sono rappresentati per mezzo di valori dei domini che compaiono nelle $n$-uple
DB Relazionale
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | DataDiNascita |
| 6554 | Rossi | Mario | 05/12/1978 |
| 8765 | Neri | Paolo | 03/11/1976 |
| 9283 | Verdi | Luisa | 12/11/1978 |
| 3456 | Rossi | Maria | 01/02/1978 |
| Esami | ||
|---|---|---|
| Studente | Voto | Corso |
| 3456 | 30 | 04 |
| 3456 | 24 | 02 |
| 9283 | 28 | 01 |
| 6554 | 26 | 01 |
| Corsi | ||
|---|---|---|
| Codice | Titolo | Docente |
| 01 | Analisi | Mario |
| 02 | Chimica | Bruni |
| 04 | Chimica | Verdi |
Struttura basata su valori
Vantaggi
- indipendenza dalla struttura fisiche (si potrebbe avere anche con puntatori HL)
- si rappresenta solo ciò che rilevante dal punto di vista dell’applicazione
- utente finale vede stessi dati del programmatore
- portabilità dei dati tra sistemi
- puntatori direzionali
Relazione su singoli attributi
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | DataDiNascita |
| 6554 | Rossi | Mario | 05/12/1978 |
| 8765 | Neri | Paolo | 03/11/1976 |
| 9283 | Verdi | Luisa | 12/11/1978 |
| 3456 | Rossi | Maria | 01/02/1978 |
| Studenti Lavoratori | |||
|---|---|---|---|
| Matricola | |||
| 6554 | |||
| 3456 | |||
Strutture Nidificate
| Da Filippo Via Roma 2, Roma | ||
| Ricevuta Fiscale 1235 del 12/01/2020 | ||
| 3 | Coperti | 3,00 |
| 2 | Antipasti | 6,20 |
| 3 | Primi | 12,00 |
| 2 | Bistecche | 18,00 |
| - | ||
| - | ||
| Totale | 39,20 | |
| Da Filippo Via Roma 2, Roma | ||
| Ricevuta Fiscale 1240 del 13/10/2020 | ||
| 2 | Coperti | 2,00 |
| 2 | Antipasti | 7,00 |
| 2 | Primi | 8,00 |
| 2 | Orate | 20,00 |
| 2 | Caffè | 2,00 |
| - | ||
| Totale | 39,00 | |
Strutture Nidificate
| Ricevute | |||||
|---|---|---|---|---|---|
| Numero | Data | Qtà | Descrizione | Importo | Totale |
| 1235 | 12/10/2020 | 3 | Coperti | 3,00 | 39,20 |
| 2 | Antipasti | 6,20 | |||
| 3 | Primi | 12,00 | |||
| 2 | Bistecche | 18,00 | |||
| 1240 | 12/10/2020 | 2 | Coperti | 2,00 | 39,00 |
| ... | ... | ... | |||
I valori devono essere semplici
Relazioni e strutture nidificate
| Ricevute | ||
|---|---|---|
| Numero | Data | Totale |
| 1235 | 12/10/2020 | 39,20 |
| 1240 | 12/10/2020 | 39,00 |
| Dettaglio | |||
|---|---|---|---|
| Numero | Qtà | Descrizione | Importo |
| 1235 | 3 | Coperti | 3,00 |
| 1235 | 2 | Antipasti | 6,20 |
| 1235 | 3 | Primi | 12,00 |
| 1235 | 2 | Bistecche | 18,00 |
| 1240 | 2 | Coperti | 2,00 |
| ... | ... | ... | ... |
Siamo stai bravi?
Abbiamo rappresentato tutti gli aspetti delle ricevute?
Dipende da cosa ci interessa:
- l’ordine delle righe è rilevante?
- possono esistere linee ripetute?
- Al bar, al servizio al tavolo, ad un gruppo:
- Cliente: “Una birra”
- Cameriere: “Se volete altre birre ditelo subito altrimenti non posso aggiungerle!”
- Sono possibili rappresentazioni diverse
Relazioni e strutture nidificate
| Ricevute | ||
|---|---|---|
| Numero | Data | Totale |
| 1235 | 12/10/2020 | 39,20 |
| 1240 | 12/10/2020 | 39,00 |
| Dettaglio | ||||
|---|---|---|---|---|
| Numero | Riga | Qtà | Descrizione | Importo |
| 1235 | 1 | 3 | Coperti | 3,00 |
| 1235 | 2 | 2 | Antipasti | 6,20 |
| 1235 | 3 | 3 | Primi | 12,00 |
| 1235 | 4 | 2 | Bistecche | 18,00 |
| 1240 | 1 | 2 | Coperti | 2,00 |
| ... | ... | ... | ... | ... |
Informazioni Incomplete
Ovvero: gestire i valori NULL
Ogni elemento in una tabella può essere o un valore del dominio oppure il valore nullo NULL
Informazione incompleta
Il modello relazionale impone una struttura rigida
- Le informazioni sono rappresentate per mezzo di $n$-uple
- Solo alcuni formati di $n$-upla sono ammessi: quelli che corrispondono agli schemi di relazione
- I dati disponibili possono non corrispondere al formato previsto
Esempio
| Capi di Stato | ||
|---|---|---|
| Nome | SecondoNome | Cognome |
| Franklin | Delano | Roosvelt |
| Winston | Churchill | |
| Charles | De Gaulle | |
| Josip | Stalin | |
NULL: come fare?
E se usassi il numero 0?
Non conviene, anche se spesso si fa, usare valori del dominio (0, stringa nulla, 99, …)
- potrebbero non esistere valori “non utilizzati”
- valori “non utilizzati” potrebbero diventare significativi
- in fase di utilizzo sarebbe necessario tener conto del significato di questi valori
Tipi di valore NULL
(Almeno) 3 casi differenti
- valore sconosciuto (quanti anni ha?)
- valore inesistente (non ha il secondo nome)
- valore non applicabile (anagrafica unica studenti/professori, i professori hanno ufficio)
I DBMS non distinguono i tipi di valore nullo
Troppi valori NULL
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | DataDiNascita |
| 6554 | Rossi | Mario | 05/12/1978 |
| 9283 | Verdi | Luisa | 12/11/1978 |
| NULL | Rossi | Maria | 01/02/1978 |
| Esami | ||
|---|---|---|
| Studente | Voto | Corso |
| NULL | 30 | NULL |
| NULL | 24 | 02 |
| 9283 | 28 | 01 |
| Corsi | ||
|---|---|---|
| Codice | Titolo | Docente |
| 01 | Analisi | Mario |
| 02 | NULL | NULL |
| 04 | Chimica | Verdi |
Vincoli di integrità
Esistono istanze di basi di dati che, pur sintatticamente corrette, non rappresentano informazioni possibili per l’applicazione di interesse.
DB Errato
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Verdi | Luisa | |
| 7876463 | Rossi | Maria | |
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 739430 | 24 | 04 | |
Vincoli di Integrità
Proprietà che deve essere soddisfatta dalle istanza che rappresentano informazioni corrette per l’applicazione
Un vincolo è una funzione booleana (un predicato): associa ad ogni istanza il valore vero o falso
Vincoli di Integrità, perché?
- Descrizione più accurata della realtà
- contributo alla “qualità dei dati”
- utili nella progettazione
- usati dai DBMS nelle interrogazioni
Vincoli di integrità: nota
Alcuni vincoli (ma non tutti) sono supportati dai DBMS
- Possiamo specificare tali vincoli e il DBMS ne impedisce violazione
- Se non supportati, la responsabilità della verifica è dell’utente/programmatore
Tipi di Vincoli
- vincoli intrarelazionali
- vincoli su valori (o di dominio)
- vincoli di $n$-upla
- vincoli interrelazionali
Vincoli di valore
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Verdi | Luisa | |
| 7876463 | Rossi | Maria | |
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 739430 | 24 | 04 | |
Voto ≥ 18 && Voto ≤ 30
Vincoli di $n$-upla
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Verdi | Luisa | |
| 7876463 | Rossi | Maria | |
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 739430 | 24 | 04 | |
Lode solo se Voto == 30
Vincoli di $n$-upla
| Stipendi | |||
|---|---|---|---|
| Impiegato | Lordo | Ritenute | Netto |
| Rossi | 55.000 | 12.500 | 42.500 |
| Verdi | 45.000 | 10.000 | 35.000 |
| Bruni | 47.000 | 11.000 | 36.000 |
Lordo = (Ritenute + Netto)
Vincoli interrelazionali
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Verdi | Luisa | |
| 7876463 | Rossi | Maria | |
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 739430 | 24 | 04 | |
Chiavi: identificare le $n$-uple
| Matricola | Cognome | Nome | Corso | Nascita |
|---|---|---|---|---|
| 27655 | Rossi | Mario | Ing inf | 5/12/78 |
| 78763 | Rossi | Mario | Ing inf | 3/11/76 |
| 65432 | Neri | Piero | Ing mecc | 10/7/79 |
| 87654 | Neri | Mario | Ing inf | 3/11/76 |
| 67653 | Rossi | Piero | Ing mecc | 5/12/78 |
Identificare le $n$-uple
- non ci sono due ennuple con lo stesso valore sull’attributo Matricola
- non ci sono due ennuple uguali su tutti e tre gli attributi Cognome, Nome e Data di Nascita
CHIAVE
Insieme di attributi che identificano le $n$-uple di una relazione
CHIAVE
Formalmente
- Un insieme di $K$ attributi è superchiave per $r$ se non contiene due $n$-uple distinte $t_1$ e $t_2$ con $t_1^K = t_2^K$
- $K$ è chiave per $r$ se è una superchiave minimale per $r$
- superchiave minimale = non contiene un’altra superchiave
Una chiave
| Matricola | Cognome | Nome | Corso | Nascita |
|---|---|---|---|---|
| 27655 | Rossi | Mario | Ing inf | 5/12/78 |
| 78763 | Rossi | Mario | Ing inf | 3/11/76 |
| 65432 | Neri | Piero | Ing mecc | 10/7/79 |
| 87654 | Neri | Mario | Ing inf | 3/11/76 |
| 67653 | Rossi | Piero | Ing mecc | 5/12/78 |
Matricola è una chiave:
- è superchiave
- contiene un solo attributo $r$ quindi è minimale
Un'altra chiave
| Matricola | Cognome | Nome | Corso | Nascita |
|---|---|---|---|---|
| 27655 | Rossi | Mario | Ing inf | 5/12/78 |
| 78763 | Rossi | Mario | Ing inf | 3/11/76 |
| 65432 | Neri | Piero | Ing mecc | 10/7/79 |
| 87654 | Neri | Mario | Ing inf | 3/11/76 |
| 67653 | Rossi | Piero | Ing mecc | 5/12/78 |
Cognome, nome, nascita è un'altra chiave:
- è superchiave
- è minimale
Un'altra chiave
| Matricola | Cognome | Nome | Corso | Nascita |
|---|---|---|---|---|
| 27655 | Rossi | Mario | Ing inf | 5/12/78 |
| 78763 | Rossi | Mario | Ing Civile | 3/11/76 |
| 65432 | Neri | Piero | Ing mecc | 10/7/79 |
| 87654 | Neri | Mario | Ing inf | 3/11/76 |
| 67653 | Rossi | Piero | Ing mecc | 5/12/78 |
Non ci sono $n$-uple uguali su Cognome e Corso:
- Cognome e Corso formano una chiave
- È sempre vero o è un caso?
Chiavi
Esistenza
- Una relazione non può contenere $n$-uple distinte ma uguali
- Ogni relazione ha come superchiave l’insieme degli attributi su cui è definita
- quindi ha (almeno) una chiave
Chiavi
Importanza
- l’esistenza delle chiavi garantisce l’accessibilità a ciascun dato della base di dati
- le chiavi permettono di correlare i dati in relazioni diverse
- il modello relazionale è basato su valori
Chiavi e valori NULL
- In presenza di valori nulli, i valori della chiave non permetteranno
- di identificare le $n$-uple
- di realizzare facilmente i riferimenti da altre relazioni
- la presenza di valori nulli nelle chiavi deve essere limitata
Chiavi e valori NULL
| Matricola | Cognome | Nome | Corso | Nascita |
|---|---|---|---|---|
| NULL | NULL | Mario | Ing inf | 5/12/78 |
| 78763 | Rossi | Mario | Ing inf | 3/11/76 |
| 65432 | Neri | Piero | Ing mecc | 10/7/79 |
| 87654 | Neri | Mario | Ing inf | NULL |
| NULL | Rossi | Piero | NULL | 5/12/78 |
Chiave primaria
- Chiave su cui non sono ammessi valori NULL
- Notazione: sottolineatura
| Matricola | Cognome | Nome | Corso | Nascita |
|---|---|---|---|---|
| 27655 | NULL | Mario | Ing inf | 5/12/78 |
| 78763 | Rossi | Mario | Ing inf | 3/11/76 |
| 65432 | Neri | Piero | Ing mecc | 10/7/79 |
| 87654 | Neri | Mario | Ing inf | NULL |
| 67653 | Rossi | Piero | NULL | 5/12/78 |
Integrità referenziale
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 787643 | 27 | e lode | 03 |
| 787643 | 24 | 04 | |
| Studenti | ||
|---|---|---|
| Matricola | Cognome | Nome |
| 276545 | Rossi | Mario |
| 787643 | Neri | Piero |
| 787642 | Bianchi | Luca |
- informazioni in relazioni diverse sono correlate attraverso valori comuni
- in particolare, valori delle chiavi (primarie)
- le correlazioni debbono essere "coerenti"
Integrità referenziale
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 787643 | 27 | e lode | 03 |
| 787647 | 24 | 04 | |
| Studenti | ||
|---|---|---|
| Matricola | Cognome | Nome |
| 276545 | Rossi | Mario |
| 787643 | Neri | Piero |
| 787642 | Bianchi | Luca |
Integrità referenziale
| Infrazioni | ||||
|---|---|---|---|---|
| Codice | Data | Vigile | Prov | Targa |
| 34321 | 1/2/95 | 3987 | MI | 39548K |
| 53524 | 4/3/95 | 3295 | TO | E39548 |
| 64521 | 5/4/96 | 3295 | PR | 839548 |
| 73321 | 5/2/98 | 9345 | PR | 839548 |
| Vigili | ||
|---|---|---|
| Matricola | Cognome | Nome |
| 3987 | Rossi | Luca |
| 3295 | Neri | Piero |
| 9345 | Neri | Mario |
| 7543 | Mori | Gino |
Integrità referenziale
| Infrazioni | ||||
|---|---|---|---|---|
| Codice | Data | Vigile | Prov | Targa |
| 34321 | 1/2/95 | 3987 | MI | 39548K |
| 53524 | 4/3/95 | 3295 | TO | E39548 |
| 64521 | 5/4/96 | 3295 | PR | 839548 |
| 73321 | 5/2/98 | 9345 | PR | 839548 |
| Auto | |||
|---|---|---|---|
| Prov | Targa | Cognome | Nome |
| MI | 39548K | Rossi | Mario |
| TO | E39548 | Rossi | Mario |
| PR | 839548 | Neri | Luca |
Vincolo di Integrità Referenziale
Un vincolo di integrità referenziale (“foreing key”) fra attributi $X$ di una relazione $r_1$ e un’altra relazione $r_2$ impone ai valori su $X$ in $r_1$ di comparire come valori della chiave primaria di $r_2$
Vincolo di Integrità Referenziale
Vincoli di integrità referenziale fra
- attributo
Vigiledella relazioneInfrazionie la relazioneVigili - attributi
Prove Numero diInfrazionie la relazioneAuto
Vincoli su più attributi
| Infrazioni | ||||
|---|---|---|---|---|
| Codice | Data | Vigile | Prov | Targa |
| 34321 | 1/2/95 | 3987 | MI | 39548K |
| 53524 | 4/3/95 | 3295 | TO | E39548 |
| 64521 | 5/4/96 | 3295 | PR | 839548 |
| 73321 | 5/2/98 | 9345 | PR | 839548 |
| Auto | |||
|---|---|---|---|
| Prov | Targa | Cognome | Nome |
| MI | E39548 | Rossi | Mario |
| TO | F34268 | Rossi | Mario |
| PR | 839548 | Neri | Luca |
Integrità referenziale e valori NULL
| Impiegati | ||
|---|---|---|
| Matricola | Cognome | Progetto |
| 34321 | Rossi | IDEA |
| 53524 | Neri | XYZ |
| 64521 | Verdi | NULL |
| 73321 | Bianchi | IDEA |
| Progetti | |||
|---|---|---|---|
| Codice | Inizio | Durata | Costo |
| IDEA | 01/2000 | 36 | 200 |
| XYZ | 07/2001 | 24 | 120 |
| BOH | 09/2001 | 24 | 150 |
Azioni compensative
Viene eliminata una $n$-upla causando una violazione
- Comportamento “standard”:
- Rifiuto dell’operazione
- Azioni compensative
- Eliminazione in cascata
- Introduzione di valori nulli
Eliminazione in cascata
| Impiegati | ||
|---|---|---|
| Matricola | Cognome | Progetto |
| 34321 | Rossi | IDEA |
| 53524 | Neri | XYZ |
| 64521 | Verdi | NULL |
| 73321 | Bianchi | IDEA |
| Progetti | |||
|---|---|---|---|
| Codice | Inizio | Durata | Costo |
| IDEA | 01/2000 | 36 | 200 |
| XYZ | 07/2001 | 24 | 120 |
| BOH | 09/2001 | 24 | 150 |
Introduzione di valori NULL
| Impiegati | ||
|---|---|---|
| Matricola | Cognome | Progetto |
| 34321 | Rossi | IDEA | 53524 | Neri | NULL |
| 64521 | Verdi | NULL |
| 73321 | Bianchi | IDEA |
| Progetti | |||
|---|---|---|---|
| Codice | Inizio | Durata | Costo |
| IDEA | 01/2000 | 36 | 200 |
| XYZ | 07/2001 | 24 | 120 |
| BOH | 09/2001 | 24 | 150 |
Vincoli multipli su più attributi
| Auto | |||
|---|---|---|---|
| Prov | Targa | Cognome | Nome |
| MI | 39548K | Rossi | Mario |
| TO | E39548 | Rossi | Mario |
| PR | 839548 | Neri | Luca |
| Incidenti | |||||
|---|---|---|---|---|---|
| Codice | Data | ProvA | TargaA | ProvB | TargaB |
| 34321 | 1/2/95 | TO | E39548 | MI | 39548K |
| 64521 | 5/4/96 | PR | 839548 | TO | E39548 |
SQL
Benefici SQL
- Indipendenza dai venditori di HW e SW
- Portabilità attraverso varia piattaforme HW
- Coperto da standard internazionali SQL1, SQL2 e SQL3
- Strategico per IBM, Oracle, Microsoft, …
- Linguaggio per data base relazionali (unico)
- Strutturato ad alto livello (English-like)
Benefici SQL
- Linguaggio programmazione (Statico/Dinamico/API)
- In grado di fornire viste diverse del data base
- Linguaggio completo (IF, triggers, …) con T-SQL e PL-SQL
- Definizione dinamica dei dati
- Client/Server
SQL Standard?
In realtà ogni motore fa un po’ come vuole
Portabilità: davvero?
Non si può fare tutto
- codici di errore non standard
- tipi di dati non sempre supportati
- tabelle di sistema non sono uguali
- definisce solo linguaggio statico, non dinamico
- sorting
SQL basics
Data Definition Language (DDL)
CREATE/DROP/ALTER TABLE/VIEW/INDEX
Data Manipulation Language (DML)
SELECT - INSERT - DELETE - UPDATE
SQL basics
Data Control Language (DCL)
GRANT - REVOKE
Transaction Control Language (TCL o T-SQL)
COMMIT - ROLLBACK
Programming Language (PL)
DECLARE - OPEN - FETCH - CLOSE
Elencare i database
SHOW DATABASES;
Ritorna l’elenco dei Database presenti nel DBMS
I comandi possono occupare anche più righe e terminano con il ;
Creare un DataBase
CREATE DATABASE nomeDataBase;
Crea un nuovo DataBase con il nome specificato e lo rende accessibile all’utente ROOT.
CREATE DATABASE IF NOT EXISTS nomeDataBase;
Crea il DB solo se non esiste già
Eliminare un DataBase
DROP DATABASE [IF EXISTS] nomeDataBase;
usiamo [...] per indicare le parti opzionali dei
comandi.
Selezionare un DataBase
USE nomeDataBase;
Tutti i comandi ora saranno riferiti a questo DB.
Definizione di dati
Istruzione CREATE TABLE;
- definisce uno schema di relazione e ne crea un’istanza vuota
specifica attributi, domini e vincoli
CREATE TABLE [IF NOT EXISTS] nomeTabella( tipo nomeAttributo1, tipo attributo2, ... tipo attributoN )
Domini - Numeri Interi
| Tipo | Byte | Minimo | Massimo |
|---|---|---|---|
| TINYINT | 1 | $-128$ | $127$ |
| SMALLINT | 2 | $-32768$ | $32767$ |
| MEDIUMINT | 3 | $-8388608$ | $8388607$ |
| INT | 4 | $-2147483648$ | $2147483647$ |
| BIGINT | 8 | $-2^{63}$ | $2^{63}-1$ |
INT(N): suggeriamo al motore di usare N
caratteri per mostrare il dato; es: INT(11)
Domini - Numeri razionali
Virgola mobile
- float - 4 bytes
- double - 8 bytes
Virgola fissa
numeric(i,n)salva esattamentencifre decimalidecimal(i,n)salva almenoncifre decimali
Domini - Testo
| Tipo | Descrizione |
|---|---|
| CHAR | Stringa di lunghezza fissa non binaria |
| VARCHAR | Stringa di lunghezza variabile non binaria |
| BINARY | Sequenza binaria a lunghezza fissa |
| VARBINARY | Sequenza binaria a lunghezza variabile |
Salvati in tabella
Domini - Generico
| Tipo | Descrizione |
|---|---|
| TINYBLOB | Binary Large OBject piccolo |
| BLOB | Binary Large OBject |
| MEDIUMBLOB | Binary Large OBject medio |
| LONGBLOB | Binary Large OBject grande |
SalvatAGGIO DEDICATO
Domini - Testo
| Tipo | Descrizione |
|---|---|
| TINYTEXT | Stringa non binaria piccola |
| TEXT | Stringa non binaria |
| MEDIUMTEXT | Stringa non binaria medio |
| LONGTEXT | Stringa non binaria grande |
SalvatAGGIO DEDICATO
Domini - Tempo
YEAR- anno nel formatoYYYYDATE- data nel formatoYYYY-MM-DDTIME- tempo nel formatohh:mm:ssDATETIME- tempo nel formatoYYYY-MM-DD hh:mm:ssTIMESTAMP- comeDATETIME, ma si aggiorna da solo
Domini - Spazio
| Tipo | Descrizione |
|---|---|
| GEOMETRY | Valore spaziale di qualsiasi tipo |
| POINT | Coordinate X, Y |
| LINESTRING | Curva (uno o più POINT) |
| POLYGON | Un poligono |
… e molti altri
Domini - Stringhe
Sto salvando testo o sequenze di byte?
- testo: devo convertire la stringa in sequenza di byte (charset)
- sequenza e basta: posso salvarla così com’è
Domini - Stringhe
Dimensione fissa o variabile?
- fissa: devo indicare una dimensione (max 255)
- variabile: occupa
lunghezza + 1; posso indicare una lunghezza massima
Domini - Stringhe
| valore | CHAR(4) | spazio | VARCHAR(4) | spazio |
|---|---|---|---|---|
'' |
'____' |
4 byte | '' |
1 byte |
'ab' |
'ab__' |
4 byte | 'ab' |
3 byte |
'abcd' |
'abcd' |
4 byte | 'abcd' |
5 byte |
'abcdef' |
'abcd' |
4 byte | 'abcd' |
5 byte |
Domini - Stringhe
Dove salvo il dato?
- nella tabella: più rapido accedere al dato per interrogazioni
- storage dedicato: anche se ho molti dati la tabella resta piccola
Studenti ed esami
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Neri | Piero | |
| 7876462 | Bianchi | Luca | |
| Corsi | ||
|---|---|---|
| Codice | Titolo | Docente |
| 01 | Analisi | Mario |
| 02 | Chimica | Bruni |
| 04 | Chimica | Verdi |
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 7876463 | 24 | 04 | |
Creare una tabella
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Neri | Piero | |
| 7876462 | Bianchi | Luca | |
CREATE TABLE Studenti(
matricola int(11),
cognome varchar(45),
nome varchar(45)
);
Cancellare una tabella
DROP TABLE [IF EXISTS] nomeTabella;
… intuitivo
DROP TABLE [IF EXISTS] nomeTabella1;
nomeTabella2,
nomeTabella3,
...;
Vincoli
Posso definire dei vincoli:
PRIMARY KEY- chiave primaria (una sola, implicaNOT NULL)NOT NULLUNIQUE- definisce chiaviCHECK- vedremo più avanti
Vincoli - Chiave primaria
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Neri | Piero | |
| 7876462 | Bianchi | Luca | |
CREATE TABLE Studenti(
matricola int(11) PRIMARY KEY,
cognome varchar(45),
nome varchar(45)
);
Vincoli - Chiave primaria
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Neri | Piero | |
| 7876462 | Bianchi | Luca | |
CREATE TABLE Studenti(
matricola int(11),
cognome varchar(45),
nome varchar(45),
PRIMARY KEY (matricola)
);
Vincoli - proibire i NULL
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Neri | Piero | |
| 7876462 | Bianchi | Luca | |
CREATE TABLE Studenti(
matricola int(11) PRIMARY KEY,
cognome varchar(45) NOT NULL,
nome varchar(45) NOT NULL
);
Vincoli - proibire i NULL
| Corsi | ||
|---|---|---|
| Codice | Titolo | Docente |
| 01 | Analisi | Mario |
| 02 | Chimica | Bruni |
| 04 | Chimica | Verdi |
CREATE TABLE Corsi(
codice int(11) PRIMARY KEY,
titolo varchar(45) NOT NULL,
docente varchar(45)
);
Vincoli - chiavi composte
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 7876463 | 24 | 04 | |
CREATE TABLE Esami(
studente int(11) PRIMARY KEY,
voto smallint NOT NULL,
lode bool,
corso int(11) PRIMARY KEY
);
Vincoli - chiavi composte
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 7876463 | 24 | 04 | |
CREATE TABLE Esami(
studente int(11),
voto smallint NOT NULL,
lode bool,
corso int(11),
PRIMARY KEY (studente, corso)
);
Not NULL + unique = Primary key
CREATE TABLE Corsi(
codice int(11) NOT NULL UNIQUE,
titolo varchar(45) NOT NULL,
docente varchar(45)
);
CREATE TABLE Esami(
studente int(11) NOT NULL UNIQUE,
voto smallint NOT NULL,
lode bool,
corso int(11) NOT NULL UNIQUE
);
UNIQUE e NULL MULTIPLI
In general, a unique constraint is violated when there is more than one row in the table where the values of all of the columns included in the constraint are equal. However, two null values are not considered equal in this comparison. That means even in the presence of a unique constraint it is possible to store duplicate rows that contain a null value in at least one of the constrained columns. This behavior conforms to the SQL standard, but we have heard that other SQL databases might not follow this rule. So be careful when developing applications that are intended to be portable.
PostgreSQL Manual
UNIQUE su più colonne
CREATE TABLE nomeTabella (
id int(11) PRIMARY KEY,
campo1 int(19),
campo2 int(12),
CONSTRAINT [nome] UNIQUE(campo1, campo2)
);
Auto Increment
- il motore si occupa di incrementare il contatore numerico
- identifico in modo chiaro una $n$-upla
ottimo come chiave primaria!
CREATE TABLE Studenti( matricola int(11) PRIMARY KEY AUTO_INCREMENT, cognome varchar(45), nome varchar(45) );
CHECK
Serve per specificare vincoli complessi
Netto = Lordo - Trattenute
- non supportato in MySql
- MySql IGNORA il comando dato alla creazione della tabella
AUTO_INCREMENT: dettagli
cosa succede se cancello una riga?
- non riciclo!
- successivo = inserito automaticamente +1
AUTO_INCREMENT: dettagli
cosa succede se imposto un valore?
- se non è duplicato viene accettato
- successivo = inserito manualmente +1
AUTO_INCREMENT: dettagli
cosa succede se modifico un valore?
- se non è duplicato viene accettato
- successivo = inserito automaticamente +1
Valori predefiniti
CREATE TABLE nome(
nomeAttributo tipo DEFAULT valore
);
Valori predefiniti
CREATE TABLE Corsi(
codice int(11) PRIMARY KEY,
titolo varchar(45) NOT NULL DEFAULT "nuovo",
docente varchar(45)
);
Commenti
CREATE TABLE nome(
nomeAttributo tipo COMMENT "commento"
);
Commenti
CREATE TABLE Corsi(
codice int(11) PRIMARY KEY,
titolo varchar(45) NOT NULL
COMMENT "Titolo del corso",
docente varchar(45)
);
Chiavi primarie e null
| Software | |||
|---|---|---|---|
| Modulo | Versione | Tipo | Data |
| Esse3 | 1.00 | alfa | 10/10/2014 |
| Esse3 | 1.00 | beta | 10/10/2014 |
| Esse3 | 1.00 | NULL | 16/11/2014 |
| Esse3 | 1.02 | alfa | 18/12/2014 |
| Esse4 | 1.00 | alfa | 12/01/2015 |
Modulo, Versione e Tipo sono una PK?
- identificano $n$-upla
- non contengono altre superchiavi
- non nulle
Chiavi primarie e null
| Software | |||
|---|---|---|---|
| Modulo | Versione | Tipo | Data |
| Esse3 | 1.00 | alfa | 10/10/2014 |
| Esse3 | 1.00 | beta | 14/11/2014 |
| Esse3 | 1.00 | NULL | 16/11/2014 |
| Esse3 | 1.02 | alfa | 18/12/2014 |
| Esse4 | 1.00 | alfa | 12/01/2015 |
- NULL = assenza di informazioni
- '' = informazione nota, pari a VUOTO
- NULL è uguale a NULL?
Chiavi primarie e null
| Software | |||
|---|---|---|---|
| Modulo | Versione | Tipo | Data |
| Esse3 | 1.00 | alfa | 10/10/2014 |
| Esse3 | 1.00 | beta | 14/11/2014 |
| Esse3 | 1.00 | '' | 16/11/2014 |
| Esse3 | 1.02 | alfa | 18/12/2014 |
| Esse4 | 1.00 | alfa | 12/01/2015 |
Vincoli Interrelazionali
FOREIGN KEYeREFERENCESe permettono di definire vincoli di integrità referenziale- di nuovo due sintassi
- per singoli attributi (non in MySql)
- su più attributi
- è possibile definire azioni compensative
FOREIGN KEY
colonne che sono FK
REFERENCES
colonne nella relazione (tabella) esterna
Studenti ed esami
| Studenti | |||
|---|---|---|---|
| Matricola | Cognome | Nome | |
| 276545 | Rossi | Mario | |
| 7876463 | Neri | Piero | |
| 7876462 | Bianchi | Luca | |
| Corsi | ||
|---|---|---|
| Codice | Titolo | Docente |
| 01 | Analisi | Mario |
| 02 | Chimica | Bruni |
| 04 | Chimica | Verdi |
| Esami | |||
|---|---|---|---|
| Studente | Voto | Lode | Corso |
| 276545 | 32 | 01 | |
| 276545 | 30 | e lode | 02 |
| 7876463 | 27 | e lode | 03 |
| 7876463 | 24 | 04 | |
Vincoli Interrelazionali
CREATE TABLE Esami(
studente int(11),
voto smallint NOT NULL,
lode bool,
corso int(11),
PRIMARY KEY (studente, corso),
FOREIGN KEY (studente) REFERENCES Studenti(matricola)
);
Definizione compatta
Non funziona ovunque (MySql)
CREATE TABLE Esami(
studente int(11) REFERENCES Studenti(matricola),
voto smallint NOT NULL,
lode bool,
corso int(11),
PRIMARY KEY (studente, corso)
);
Vincoli Interrelazionali
CREATE TABLE Esami(
studente int(11),
voto smallint NOT NULL,
lode bool,
corso int(11),
PRIMARY KEY (studente, corso),
FOREIGN KEY (studente) REFERENCES Studenti(matricola)
FOREIGN KEY (corso) REFERENCES Corsi(codice)
);
Vincoli Interrelazionali con nome
CREATE TABLE Esami(
studente int(11),
voto smallint NOT NULL,
lode bool,
corso int(11),
PRIMARY KEY (studente, corso),
CONSTRAINT FK_Studente FOREIGN KEY (studente) REFERENCES Studenti(matricola)
CONSTRAINT FK_Corso FOREIGN KEY (corso) REFERENCES Corsi(codice)
);
Disattivare i vincoli interrelazionali
- sto caricando i dati: ordine importante, altrimenti errore
- voglio disattivare temporaneamente i vincoli
- disattivazione
SET foreign_key_checks = 0
- riattivazione
SET foreign_key_checks = 1
Integrità referenziale
| Infrazioni | ||||
|---|---|---|---|---|
| Codice | Data | Vigile | Prov | Targa |
| 34321 | 1/2/95 | 3987 | MI | 39548K |
| 53524 | 4/3/95 | 3295 | TO | E39548 |
| 64521 | 5/4/96 | 3295 | PR | 839548 |
| 73321 | 5/2/98 | 9345 | PR | 839548 |
| Automobile | |||
|---|---|---|---|
| Prov | Targa | Cognome | Nome |
| MI | 39548K | Rossi | Mario |
| TO | E39548 | Rossi | Mario |
| PR | 839548 | Neri | Luca |
| Vigili | ||
|---|---|---|
| Matricola | Cognome | Nome |
| 3987 | Rossi | Luca |
| 3295 | Neri | Piero |
| 9345 | Neri | Mario |
| 7543 | Mori | Gino |
Integrità referenziale
| Vigili | ||
|---|---|---|
| Matricola | Cognome | Nome |
| 3987 | Rossi | Luca |
| 3295 | Neri | Piero |
| 9345 | Neri | Mario |
| 7543 | Mori | Gino |
CREATE TABLE Vigili(
matricola int(11) PRIMARY KEY AUTO_INCREMENT,
cognome varchar(45) NOT NULL,
nome varchar(45) NOT NULL
);
Integrità referenziale
| Automobile | |||
|---|---|---|---|
| Prov | Targa | Cognome | Nome |
| MI | 39548K | Rossi | Mario |
| TO | E39548 | Rossi | Mario |
| PR | 839548 | Neri | Luca |
CREATE TABLE Automobile(
prov char(2),
targa char(6),
cognone varchar(45) NOT NULL,
nome varchar(45) NOT NULL,
PRIMARY KEY (prov, targa)
);
Integrità referenziale
| Infrazioni | ||||
|---|---|---|---|---|
| Codice | Data | Vigile | Prov | Targa |
| 34321 | 1/2/95 | 3987 | MI | 39548K |
| 53524 | 4/3/95 | 3295 | TO | E39548 |
| 64521 | 5/4/96 | 3295 | PR | 839548 |
| 73321 | 5/2/98 | 9345 | PR | 839548 |
CREATE TABLE Infrazioni(
codice int(11) PRIMARY KEY AUTO_INCREMENT,
data datetime,
vigile int(11),
prov char(2),
targa char(6),
FOREIGN KEY (vigile) REFERENCES Vigili(matricola),
FOREIGN KEY (prov, targa)
REFERENCES Automobile(prov, targa)
);
Cancellazione
CREATE TABLE Infrazioni(
codice int(11) PRIMARY KEY AUTO_INCREMENT,
data datetime NOT NULL,
vigile int(11),
prov char(2) NOT NULL,
targa char(6) NOT NULL,
FOREIGN KEY (vigile) REFERENCES Vigili(matricola)
ON DELETE SET NULL ON UPDATE CASCADE,
FOREIGN KEY (prov, targa) REFERENCES
Automobile(prov, targa)
);
Cambiare lo schema
| Infrazioni | |||||
|---|---|---|---|---|---|
| Codice | Data | dataModifica | Vigile | Prov | Targa |
| 34321 | 1/2/95 | 1/2/95 | 3987 | MI | 39548K |
| 53524 | 4/3/95 | 16/4/91 | 3295 | TO | E39548 |
| 64521 | 5/4/96 | 11/2/84 | 3295 | PR | 839548 |
| 73321 | 5/2/98 | 31/12/98 | 9345 | PR | 839548 |
Cambiare lo schema
DROPtabella- ricreare tabella
- … perdo tutti i dati
Modificare tabelle
ALTER TABLE nomeTabella
azione1
[, azione2, ...]
- aggiungere/togliere colonne
- cambiare il tipo di dato
- rinominare la tabella
- definire chiavi primarie, esterne, ecc..
Aggiungere colonne
ALTER TABLE nomeTabella
ADD COLUMN definizioneColonna
[ FIRST | AFTER nomeColonna ]
Aggiungere colonne
ALTER TABLE Infrazioni
ADD COLUMN dataModifica TIMESTAMP
AFTER data
Rimuovere colonne
ALTER TABLE nomeTabella
DROP COLUMN nomeColonna
Rimuovere colonne
ALTER TABLE infrazioni
DROP COLUMN dataModifica
Modificare colonne
ALTER TABLE nomeTabella
CHANGE COLUMN nomeOriginale
nomeNuovo tipo
Modificare colonne
ALTER TABLE infrazioni
CHANGE COLUMN dataModifica
dataUltimaModifica TIMESTAMP
Modificare colonne
ALTER TABLE automobili
CHANGE COLUMN cognome
VARCHAR(100)
Rinominare tabelle
ALTER TABLE nomeTabella
RENAME TO nuovoNome
Rinominare tabelle
ALTER TABLE infrazioni
RENAME TO odiateInfrazioni
Aggiungere/Rimuovere Foreign Key
ALTER TABLE nomeTabella
ADD CONSTRAINT nome
FOREIGN KEY (...)
REFERENCES tabella(...)
ALTER TABLE nomeTabella
DROP FOREIGN KEY nome
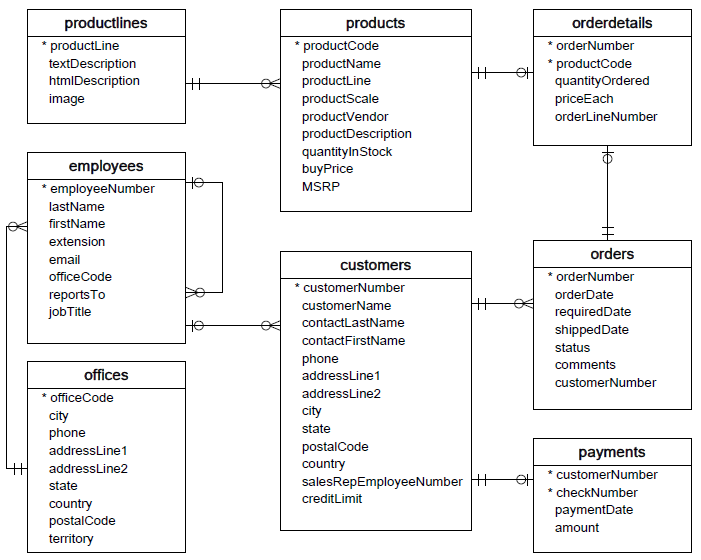
DataBase di prova
classicmodels
vendita modellini
https://www.mysqltutorial.org/getting-started-with-mysql/mysql-sample-database-aspx/
DataBase di prova
classicmodels
- clienti
- dipendenti
- uffici di vendita
- prodotti
- ordini
- pagamenti
DataBase di prova
classicmodels
- customers: dati dei clienti
- products: modellini disponibili
- productlines: linee di prodotti
- auto classiche, moto, navi, treni
- orders: ordini fatti dai clienti
DataBase di prova
classicmodels
- orderdetails: dettagli di ogni ordine dei clienti
- linee dell’ordine
- payments: pagamenti fatti dai clienti
- employees: informazioni sui dipendenti
- chi è il capo di chi, telefoni, ecc
- offices: uffici di vendita
Elencare elementi della tabella
Elencare tutti i modellini in vendita
SELECT * FROM products;
Istruzione select (base)
SELECT attributo1 [, attributo2, ...]
FROM tabella1 [, tabella2, ...]
[WHERE condizione]
*= tutti gli attributiFROM= da dove (per ora)WHERE= quali ennuple
Tutto è una tabella
- selezione:
WHERE- selezione una “sottotabella”
- proiezione: elenco attributi
- mostro una tabella scegliendo quali colonne mostrare
Selezione
Mostra i modellini che costano meno di 75$
SELECT * FROM products WHERE MSRP < 75;
Selezione e proiezione
Mostra nome, prezzo di acquisto e di vendita dei modellini che costano meno di 75$
SELECT productName, buyPrice, MSRP
FROM products
WHERE MSRP < 75;
Rinominare attributi
istruzione AS
SELECT productName AS nomeProdotto,
productVendor AS nomeVenditore
FROM products;
SELECT, abbreviazioni
SELECT productName, buyPrice, MSRP
FROM products
WHERE MSRP < 75;
in realtà stiamo scrivendo
SELECT p.productName, p.buyPrice, p.MSRP
FROM products p
WHERE p.MSRP < 75;
SELECT, abbreviazioni
SELECT * FROM products;
in realtà stiamo scrivendo
SELECT productCode, productName, productLine,
productScale, productVendor,
productDescription, quantityInStock,
buyPrice, MSRP
FROM products;
SELECT, abbreviazioni
SELECT * FROM products;
in realtà stiamo scrivendo
SELECT productCode, productName, productLine,
productScale, productVendor,
productDescription, quantityInStock,
buyPrice, MSRP
FROM products
WHERE true;
Condizioni: testo esatto
Mostra tutti i dipendenti di nome Leslie
SELECT * FROM employees
WHERE firstName = 'Leslie';
Virgolette singole o doppie?
"Leslie"o'Leslie'?- indifferente!
- standard ANSI:
'Leslie'
Virgolette singole o doppie?
per inserire ‘ in una stringa? Es: Ci'ao
- delimitata da
" ":"Ci'ao" - delimitata da
' ': raddoppio →'Ci''ao'
per inserire ‘ in una stringa? Es: Ci"'"ao
- delimitata da
" ": raddoppio →"Ci""ao" - delimitata da
' ':'Ci"ao'
Condizioni: testo incompleto
Mostra tutti i dipendenti il cui cognome finisce per “son”.
SELECT * FROM employees
WHERE lastName LIKE '%son';
Condizioni: testo incompleto
Mostra tutti i dipendenti il cui cognome NON finisce per “son”.
SELECT * FROM employees
WHERE lastName NOT LIKE '%son';
Condizioni: testo incompleto
%= zero o più caratteri_= esattamente un carattere- per cercare il carattere
%uso\% - per cercare il carattere
_uso\_
Condizioni: testo incompleto
Mostra tutti i dipendenti il cui nome finisce per "arry" e davanti ha una sola lettera
SELECT * FROM employees
WHERE firstName LIKE '_arry';
Condizioni: testo incompleto
Mostra tutti i prodotti che hanno una scala divisibile per 10 e minore di 100 (es: 1:10, 1:20, 1:30, ...)
SELECT * FROM products
WHERE productScale LIKE '1:_0';
Condizioni: testo incompleto
Mostra tutti i dipendenti il cui nome inizia con M e la cui terza lettera è una r
SELECT * FROM employees
WHERE firstName LIKE 'M_r%';
Più condizioni
Mostra i modellini che costano meno di 75 e che abbiamo comprato a più di 30
SELECT productName, MSRP, buyPrice
FROM products
WHERE MSRP < 75 AND buyPrice > 30;
Più condizioni
Mostra i modellini che costano meno di 75 o più di 150
SELECT productName, MSRP
FROM products
WHERE MSRP < 75 OR MSRP > 150;
Più condizioni
Mostra i modellini che costano meno di 75 o più di 150 e che comunque abbiamo comprato a più di 30
SELECT productName, MSRP, buyPrice
FROM products
WHERE (MSRP<75 OR MSRP>150) AND buyPrice>30;
Intervalli
Seleziona i valori compresi tra x e y (inclusi)
SELECT ... FROM ...
WHERE colonna BETWEEN x AND y;
Intervalli
Mostra i pagamenti con importi compresi tra 5.000 ed 8.000
SELECT * FROM payments
WHERE amount BETWEEN 5000 AND 8000;
Intervalli
Mostra i pagamenti con importi compresi tra 5.000 ed 8.000
SELECT * FROM payments
WHERE amount BETWEEN 5000 AND 8000;
forma equivalente
SELECT * FROM payments
WHERE amount >= 5000 AND
amount <= 8000;
Intervalli
Prendi tutti i dipendenti il cui nome inizia con una lettera tra B ed F
SELECT * FROM employees
WHERE firstName BETWEEN 'B' AND 'F';
Liste
Controlla se il valore è presente in una lista di valori
SELECT ... FROM ...
WHERE colonna IN (val1, val2, ...)
Liste
Mostra codice ufficio, città e numero di telefono degli uffici in Francia o America
SELECT officeCode, city, phone
FROM offices
WHERE country IN ('USA', 'FRANCE');
Liste
SELECT officeCode, city, phone
FROM offices
WHERE country IN ('USA', 'FRANCE');
forma equivalente
SELECT officeCode, city, phone
FROM offices
WHERE country = 'USA' OR
country = 'FRANCE';
Liste
Mostrare i modellini del tipo "Planes", "Ships" o "Classic Cars"
SELECT * FROM products
WHERE productLine
IN ('Planes','Ships','Classic Cars');
Gestire i NULL
SELECT ... FROM ...
WHERE colonna = "";
NO
Gestire i NULL
SELECT ... FROM ...
WHERE colonna IS NULL;
Gestire i NULL
Mostra gli ordini non spediti
SELECT * FROM orders
WHERE shippedDate IS NULL;
Gestire i NULL
Mostra gli ordini creati dopo il 30/04/2005 e non spediti
SELECT * FROM orders WHERE
orderDate > '2005-04-30' AND
shippedDate IS NULL;
Espressioni
Mostra i prezzi di vendita senza l’IVA (prezzo / 1.22)
SELECT productName, MSRP/1.22 AS noIVA
FROM products;
Espressioni
Mostra i prodotti con un margine superiore a 50
SELECT productName, MSRP, buyPrice
FROM products
WHERE MSRP-buyPrice > 50;
Funzioni
Stringhe
length()reverse()right()trim()- …
Funzioni
Mostra i prodotti con nomi di almeno 15 caratteri.
SELECT productName, length(productName)
FROM products
WHERE length(productName) >= 15;
Funzioni
Data e ora
day()year()now()month()monthname()- …
Funzioni
Mostra i prodotti orinati nel mese di gennaio
SELECT * from orders
WHERE month(orderDate) = 1;
Ordinamento
Stabilire l’ordine di presentazione dei risultati
SELECT ... FROM ... WHERE ...
ORDER BY col1 [ASC|DESC], col2 [ASC|DESC], ...
ASC: crescente → DEFAULT!DESC: decrescente
Ordinamento
Mostra i modellini ordinandoli per prezzo di vendita crescente
SELECT productName, MSRP
FROM products
ORDER BY MSRP;
Ordinamento
Mostra i clienti ordinandoli per paese crescente e credito massimo decrescente
SELECT customerName, country, creditLimit
FROM customers
ORDER BY country, creditLimit DESC;
Ordinamento
Mostra gli ordini ordinandoli in base allo status in cui si trovano (in corso, in attesa, cancellati, ecc).
SELECT * FROM orders
order by status;
NO
Ordinamento
Mostra gli ordini ordinandoli in base allo status in cui si trovano (in corso, in attesa, cancellati, ecc)
FIELD(text, str1, str2, str3, ...)
Ritorna la posizione della stringa text nella lista str1, str2, str3, …
Ordinamento
Mostra gli ordini ordinandoli in base allo status in cui si trovano (in corso, in attesa, cancellati, ecc).
SELECT * FROM orders
ORDER BY FIELD(status, 'In Process',
'On Hold', 'Cancelled', 'Resolved',
'Disputed','Shipped');
Uniamo il tutto...
Mostra i prodotti venduti a meno di 100€, mettendo in cima quelli con il margine più alto
SELECT productName,
MSRP-buyPrice as margine
FROM products
WHERE MSRP < 100
ORDER BY msrp-buyPrice DESC
Righe Duplicate
Ogni tanto le nostre query ritornano righe
duplicate: come facciamo ad eliminare i doppioni?
SELECT DISTINCT ... FROM ...
Righe Duplicate
Mostra tutte le città in cui si trovano i miei clienti, ordinandole alfabeticamente
SELECT DISTINCT city FROM customers
order by city;
Decodificare le relazioni
Prodotto cartesiano
Creo il prodotto cartesiano di più tabelle
SELECT ... FROM tabella1, tabella2, ...
Risultato: una riga per ogni combinazione di valori tra le righe di tabella1 e di tabella2
Prodotto cartesiano
Crea il prodotto cartesiano tra la tabella degli
impiegati e quella dei clienti
SELECT * FROM customers, employees;
Cross Join
Crea il prodotto cartesiano tra la tabella degli
impiegati e quella dei clienti
SELECT * FROM customers, employees;
Forma esplicita:
SELECT * FROM customers CROSS JOIN employees;
Prodotto Cartesiano Filtrato
Non voglio vedere tutte le combinazioni, solo filtrare tabella!
SELECT ... FROM tabella1, tabella2, ...
WHERE condizione sui valori comuni (PK e FK)
Creo una riga per ogni combinazione di valori tra le righe della tabella1 e della tabella2, ma poi salvo solo quelle sensate
Prodotto Cartesiano Filtrato
Mostra per ogni cliente il nome del venditore associato
SELECT customerName, salesRepEmployeeNumber,
lastName, employeeNumber
FROM customers, employees
WHERE salesRepEmployeeNumber = employeeNumber
Inner Join
Modo migliore per scrivere il tutto
SELECT ... FROM tabella1
INNER JOIN tabella2
ON PK = FK
Inner Join
Mostra per ogni cliente il nome del venditore associato
SELECT customerName, salesRepEmployeeNumber,
lastName, employeeNumber
FROM customers
INNER JOIN employees
ON salesRepEmployeeNumber = employeeNumber;
Inner Join ad ambiguità
Ogni tanto PK e FK hanno stesso nome
SELECT ... FROM tabella1
INNER JOIN tabella2
ON tabella2.PK = tabella1.FK
Inner Join ad ambiguità
Mostra per ogni prodotto la descrizione della linea di prodotti cui appartiene
SELECT productCode, productName, textDescription
FROM products INNER JOIN productlines
ON products.productline =
productlines.productline;
Inner Join ad ambiguità
SELECT productCode, productName, textDescription
FROM products INNER JOIN productlines
ON products.productline = productlines.productline;
Inner Join ad ambiguità
Forma equivalente
SELECT productCode, productName, textDescription
FROM products p1
INNER JOIN productlines p2
ON p1.productline = p2.productline;
Inner Join
Mostra per ogni prodotto la descrizione della linea di prodotti cui appartiene
SELECT productCode, productName, textDescription
FROM products INNER JOIN productlines
ON products.productline =
productlines.productline;
Criteri di Join
Se gli attributi hanno lo stesso nome tra le relazioni, si può usare una forma abbreviata
SELECT productCode, productName,
textDescription
FROM products INNER JOIN productlines
USING(productline);
Criteri di Join
Mostra tutti gli impiegati e la città in cui si trova l’ufficio cui afferiscono
SELECT firstName, lastName, city
FROM employees INNER JOIN offices
USING (officeCode);
Criteri di Join
Se gli unici nomi di attributi in comune tra due tabelle sono quelli di FK/PK, si può usare una forma ANCORA più abbreviata
SELECT ... FROM tabella1
NATURAL JOIN tabella2
pericolose!
Cosa succede se aggiungo/cambio colonne?
Criteri di Join
Mostra per ogni prodotto la descrizione della linea di prodotti cui appartiene
SELECT productCode, productName,
textDescription
FROM products NATURAL JOIN productlines;
Problema
- Voglio vedere i clienti ✓
- Voglio vedere il nome dei venditori assegnati ✓
- Voglio vedere anche i clienti senza venditore assegnato (?)
Left Outer Join
Mostra tutti i dati della prima tabella, e se possibile associa le informazioni della seconda
SELECT ... FROM tabella1
LEFT OUTER JOIN tabella2
ON PK = FK
Left Outer Join
Mostra tutti i clienti; se il cliente ha un venditore associato, mostrane i dati
SELECT customerName, concat(firstName,' ',lastName)
FROM customers LEFT OUTER JOIN employees
ON salesRepEmployeeNumber = employeeNumber
Left Outer Join
Mostra tutti i clienti; se il cliente ha un venditore associato, mostrane i dati
SELECT customerName, concat(firstName,' ',lastName)
FROM customers LEFT OUTER JOIN employees
ON salesRepEmployeeNumber = employeeNumber
forma equivalente
SELECT customerName, concat(firstName,' ',lastName)
FROM customers LEFT JOIN employees
ON salesRepEmployeeNumber = employeeNumber
Inner vs Left Outer Join
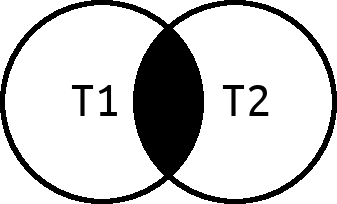
Inner

Left Outer
Left Outer Join
Mostra tutti i clienti ed i relativi ordini, inclusi i clienti che non hanno fatto ordini
SELECT c.customerNumber, c.customerName,
o.orderNumber, o.status
FROM customers c LEFT JOIN orders o
ON c.customerNumber = o.customerNumber;
Left Outer Join
Mostra tutti i clienti che non hanno ordini
SELECT c.customerNumber, c.customerName,
orderNumber, o.status
FROM customers c LEFT JOIN orders o
ON c.customerNumber = o.customerNumber
WHERE orderNumber is NULL
Right Outer Join
Mostra tutti i dati della SECONDA tabella, e se possibile associa le informazioni della prima
SELECT ... FROM tabella1
RIGHT OUTER JOIN tabella2
ON PK = FK
Inner vs Left vs Right Outer Join
Inner
Left Outer

Right Outer
Right Outer Join
Mostra tutti i clienti ed i relativi ordini, inclusi i clienti che non hanno fatto ordini
SELECT c.customerNumber, c.customerName,
orderNumber, o.status
FROM orders o RIGHT JOIN customers c
ON c.customerNumber = o.customerNumber
Join Multiple
Decodificare il contenuto di più tabelle in una sola query
SELECT ... FROM tabella1
[INNER|LEFT|RIGHT]JOIN tabella2
ON PK = FK
[INNER|LEFT|RIGHT]JOIN tabella3
ON PK = FK
Join Multiple
Mostra tutti i clienti, il nome dell’impiegato associato ed il numero di telefono dell’ufficio
SELECT c.customerName, e.firstName, o.phone
FROM customers c
LEFT JOIN employees e
ON c.salesRepEmployeeNumber = e.employeeNumber
LEFT JOIN offices o
USING (officeCode)
Join Multiple
Stampare ogni riga dell’ordine, indicando il nome del cliente, numero d’ordine ed il nome del prodotto ordinato
SELECT c.customerName, o.orderNumber, p.productName
FROM orderdetails d
INNER JOIN orders o
USING (orderNumber)
INNER JOIN customers c
USING (customerNumber)
INNER JOIN products p
USING (productCode)
ORDER BY o.orderNumber, d.orderLineNumber;
Join multiple
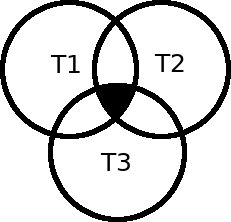
Inner + Inner
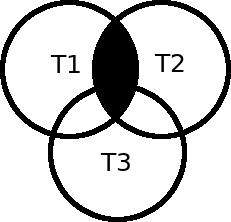
Inner + Left Outer
Cross Join
| ID | Nome | Prezzo | Linea |
|---|---|---|---|
| 1 | Audi A5 | 50,00 | A |
| 2 | Mercedes C | 45,00 | A |
| 3 | Smart | 25,00 | B |
| ID | Nome | Link |
|---|---|---|
| A | Auto Sportive | ... |
| B | Micro Auto | ... |
| ID | Nome | Prezzo | Linea | ID | Nome | Link |
|---|---|---|---|---|---|---|
| 1 | Audi A5 | 50,00 | A | A | Auto Sportive | ... |
| 1 | Audi A5 | 50,00 | A | B | Micro Auto | ... |
| 2 | Mercedes C | 45,00 | A | A | Auto Sportive | ... |
| 2 | Mercedes C | 45,00 | A | B | Micro Auto | ... |
| 3 | Smart | 25,00 | B | A | Auto Sportive | ... |
| 3 | Smart | 25,00 | B | B | Micro Auto | ... |
Inner Join
| ID | Nome | Prezzo | Linea |
|---|---|---|---|
| 1 | Audi A5 | 50,00 | A |
| 2 | Mercedes C | 45,00 | A |
| 3 | Smart | 25,00 | B |
| ID | Nome | Link |
|---|---|---|
| A | Auto Sportive | ... |
| B | Micro Auto | ... |
| ID | Nome | Prezzo | Linea | ID | Nome | Link |
|---|---|---|---|---|---|---|
| 1 | Audi A5 | 50,00 | A | A | Auto Sportive | ... |
| 2 | Mercedes C | 45,00 | A | A | Auto Sportive | ... |
| 3 | Smart | 25,00 | B | B | Micro Auto | ... |
Inner Join e NULL
| ID | Nome | Prezzo | Linea |
|---|---|---|---|
| 1 | Audi A5 | 50,00 | A |
| 2 | Mercedes C | 45,00 | NULL |
| 3 | Smart | 25,00 | B |
| ID | Nome | Link |
|---|---|---|
| A | Auto Sportive | ... |
| B | Micro Auto | ... |
| ID | Nome | Prezzo | Linea | ID | Nome | Link |
|---|---|---|---|---|---|---|
| 1 | Audi A5 | 50,00 | A | A | Auto Sportive | ... |
| 3 | Smart | 25,00 | B | B | Micro Auto | ... |
Left Outer Join
| ID | Nome | Prezzo | Linea |
|---|---|---|---|
| 1 | Audi A5 | 50,00 | A |
| 2 | Mercedes C | 45,00 | NULL |
| 3 | Smart | 25,00 | B |
| ID | Nome | Link |
|---|---|---|
| A | Auto Sportive | ... |
| B | Micro Auto | ... |
| ID | Nome | Prezzo | Linea | ID | Nome | Link |
|---|---|---|---|---|---|---|
| 1 | Audi A5 | 50,00 | A | A | Auto Sportive | ... |
| 2 | Mercedes C | 45,00 | NULL | NULL | NULL | NULL |
| 3 | Smart | 25,00 | B | B | Micro Auto | ... |
Join Multiple
| ID | Nome | Colore | Linea |
|---|---|---|---|
| 1 | Audi A5 | 1 | A |
| 2 | Mercedes C | 2 | A |
| 3 | Smart | 2 | B |
| ID | Nome | Link |
|---|---|---|
| A | Auto Sportive | ... |
| B | Micro Auto | ... |
| ID | Colore |
|---|---|
| 1 | Rosso |
| 2 | Blu |
| ID | Nome | Prezzo | Linea | ID | Nome | Link | ||
|---|---|---|---|---|---|---|---|---|
| 1 | Audi A5 | 1 | A | A | Auto Sportive | ... | 1 | Rosso |
| 2 | Mercedes C | 2 | A | A | Auto Sportive | ... | 2 | Blu |
| 3 | Smart | 2 | B | B | Micro Auto | ... | 2 | Blu |
Full Outer Join
Mostra tutti i dati della prima tabella, e se possibile associa le informazioni della seconda.
Mostra comunque tutti i dati della seconda tabella.
SELECT ... FROM tabella1
FULL OUTER JOIN tabella2
ON PK = FK
Join Multiple
| ID | Veicolo | Colore | Persona |
|---|---|---|---|
| 1 | Automobile | 1 | 4 |
| 2 | Bici | 2 | NULL |
| 3 | Moto | NULL | 1 |
| 4 | Scooter | 3 | 3 |
| ID | Cognome |
|---|---|
| 1 | Rossi |
| 2 | Bianchi |
| 3 | Bassi |
| 4 | Scaini |
| ID | Colore |
|---|---|
| 1 | Verde |
| 2 | Giallo |
| 3 | Blu |
Persone che possiedono veicoli colorati
SELECT v.veicolo, c.colore, p.cognome
FROM veicolo v
INNER JOIN persona p ON v.id = p.id
INNER JOIN colore c ON v.colore = c.id ;| Veicolo | Colore | Cognome |
|---|---|---|
| Automobile | Verde | Scaini |
| Scooter | Blu | Bassi |
Join Multiple
| ID | Veicolo | Colore | Persona |
|---|---|---|---|
| 1 | Automobile | 1 | 4 |
| 2 | Bici | 2 | NULL |
| 3 | Moto | NULL | 1 |
| 4 | Scooter | 3 | 3 |
| ID | Cognome |
|---|---|
| 1 | Rossi |
| 2 | Bianchi |
| 3 | Bassi |
| 4 | Scaini |
| ID | Colore |
|---|---|
| 1 | Verde |
| 2 | Giallo |
| 3 | Blu |
Persone che possiedono veicoli colorati o nessun veicolo
SELECT v.veicolo, c.colore, p.cognome
FROM persona p
LEFT JOIN veicolo ON v.id = p.id
INNER JOIN colore c ON v.colore = c.id ;| Veicolo | Colore | Cognome |
|---|---|---|
| Automobile | Verde | Scaini |
| Scooter | Blu | Bassi |
Join Multiple
| ID | Veicolo | Colore | Persona |
|---|---|---|---|
| 1 | Automobile | 1 | 4 |
| 2 | Bici | 2 | NULL |
| 3 | Moto | NULL | 1 |
| 4 | Scooter | 3 | 3 |
| ID | Cognome |
|---|---|
| 1 | Rossi |
| 2 | Bianchi |
| 3 | Bassi |
| 4 | Scaini |
| ID | Colore |
|---|---|
| 1 | Verde |
| 2 | Giallo |
| 3 | Blu |
Persone che possiedono veicoli colorati o nessun veicolo
SELECT v.veicolo, c.colore, p.cognome
FROM veicolo v
INNER JOIN colore c ON v.colore = c.id
RIGHT JOIN persona p ON v.id = p.id;| Veicolo | Colore | Cognome |
|---|---|---|
| Automobile | Verde | Scaini |
| Scooter | Blu | Bassi |
| Rossi | NULL | NULL |
| Bianchi | NULL | NULL |
Self join
Join di una tabella con se stessa
SELECT ... FROM tabella1
[LEFT|RIGHT|INNER] JOIN tabella1
ON PK = FK
- avrò sicuramente nomi di attributi duplicati
- dovrò introdurre degli alias
Self Join
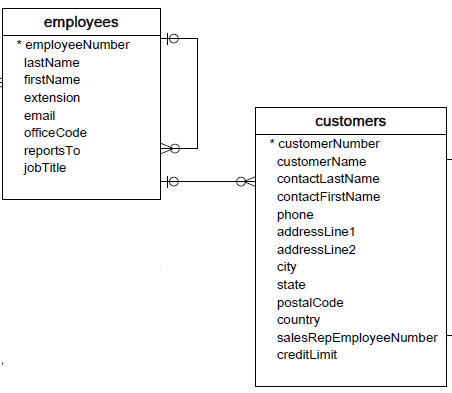
| employeeNumber | firstName | lastName | reportsTo |
|---|---|---|---|
| 1002 | Diane | Murphy | NULL |
| 1056 | Mary | Patterson | 1002 |
| 1076 | Jeff | Firrelli | 1056 |
| 1088 | William | Patterson | 1056 |
Self Join
Mostra tutti i dipendenti ed il nome del loro capo
SELECT m.employeeNumber, m.firstName,
m.lastName, m.reportsTo, c.firstName,
c.lastName FROM employees m
LEFT JOIN employees c
ON m.reportsTo = c.employeeNumber;
Self Join
Mostra tutte le coppie di clienti che abitano nella stessa città
SELECT c1.city, c1.customerName,
c2.customerName
FROM customers c1 INNER JOIN customers c2
ON c1.city = c2.city;
NO
Self Join
Mostra tutte le coppie di clienti che abitano nella stessa città
SELECT c1.city, c1.customerName,c2.customerName
FROM customers c1 INNER JOIN customers c2
ON c1.city = c2.city AND
c1.customername <> c2.customerName
Self Join
Mostra tutte le coppie di clienti che abitano nella stessa città
SELECT c1.city, c1.customerName,c2.customerName
FROM customers c1 INNER JOIN customers c2
ON c1.city = c2.city AND
c1.customername <> c2.customerName
forma equivalente
SELECT c1.city, c1.customerName,c2.customerName
FROM customers c1 INNER JOIN customers c2
ON c1.city = c2.city
WHERE c1.customername <> c2.customerName
Union join
Unisce i risultati di più query
SELECT ... FROM ...
UNION [DISTINCT | ALL]
SELECT ... FROM ...
[UNION [DISTINCT | ALL]
SELECT ... FROM ...]
ATTENZIONE!
- stesso numero di attributi
- attributi omogenei
UNION
SELECT ... FROM ...
UNION [DISTINCT | ALL]
SELECT ... FROM ...
[UNION [DISTINCT | ALL]
SELECT ... FROM ...]
DISTINCT: default, elimina duplicatiALL: se specificato, NON elimina duplicati
UNION
Mostra l’identificativo ed il nome di tutti gli impiegati e di tutti i clienti
SELECT customerNumber AS id,contactLastname AS name
FROM customers
UNION
SELECT employeeNumber AS id, firstname AS name
FROM employees;
UNION
Mostra l’identificativo ed il nome di tutti gli impiegati e di tutti i clienti
SELECT customerNumber,contactLastname
FROM customers
UNION
SELECT employeeNumber, firstname
FROM employees;
- Se non specifico l’alias prende i nomi della prima query
UNION
Mostra l’id ed il nome di tutti gli impiegati e di tutti i clienti, scrivendo per ognuno cosa sia
SELECT customerNumber AS id,
contactLastname AS name, "Cliente" AS tipo
FROM customers
UNION
SELECT employeeNumber AS id,
concat(firstname," ",lastname) AS name,
"Impiegato" AS tipo
FROM employees;
UNION e ordinamento
E se volessi ordinare i risultati?
SELECT ... FROM ...
UNION [DISTINCT | ALL]
SELECT ... FROM ...
ORDER BY criteri
ATTENZIONE!
- l’ultima riga è riferita al RISULTATO della union, non all’ultima query
- se si inserisce la clausola all’interno della singola query verrà ignorata
UNION e ordinamento
Posso usare le parentesi per fare ordine
(SELECT ... FROM ...)
UNION [DISTINCT | ALL]
(SELECT ... FROM ...)
ORDER BY criteri
Union ed ordinamento
Mostrare id e nome di clienti ed impiegati ordinandoli per nome
(SELECT customerNumber AS id,
contactLastname AS name
FROM customers)
UNION
(SELECT employeeNumber AS id, firstname AS name
FROM employees)
ORDER BY name;
Union ed ordinamento
Mostrare i paesi in cui c’è un ufficio o un cliente, ordinati per nome
SELECT country FROM offices
UNION
SELECT country FROM customers
ORDER BY country;
Intersect
Restituisce l’intersezione di più query
SELECT ... FROM ...
INTERSECT
SELECT ... FROM ...
INTERSECT
SELECT ... FROM ...
Non c’è in MySql, servono query nidificate
Raggruppare i dati
Voglio raggruppare le ennuple in sottogruppi in base ad uno o più valori
SELECT a1 , a2 ,...,an
FROM tabella1 WHERE condizioni
GROUP BY a1, a2,...,an
Raggruppare i dati
Mostra tutti gli stati degli ordini esistenti
SELECT status
FROM orders
GROUP BY status
Raggruppare i dati
Mostra tutti gli stati degli ordini fatti prima del 31/12/2003
SELECT status
FROM orders
WHERE orderDate < "2003-12-31"
GROUP BY status;
Raggruppare i dati
Mostra tutti gli stati degli ordini fatti prima del 31/12/2003
SELECT status
FROM orders
WHERE orderDate < "2003-12-31"
GROUP BY status;
forma equivalente
SELECT DISTINCT status
FROM orders
WHERE orderDate < "2003-12-31"
Funzioni di aggregazione
Permettono di effettuare calcoli su tutti i valori che l’attributo assume nella query eseguita
SELECT a1, a2, ..., an, aggregatore(ax)
FROM tabella1 WHERE condizioni
Esempio:
- quanti ordini sono stati fatti?
- quanto costa in media un prodotto?
Funzioni di aggregazione
SELECT a1, a2, ..., an, aggregatore(ax)
FROM tabella1 WHERE condizioni
Aggregatori:
COUNT: conta il numero di valori presentiSUM: somma dei valoriAVG: media dei valoriMAX/MIN: massimo e minimo
Funzioni di aggregazione
Quanti dipendenti ci sono in azienda?
SELECT count(*)
FROM employees;
Funzioni di aggregazione - NULL
Differenza fra
SELECT count(*)
FROM employees
e
SELECT count(reportsTo)
FROM employees
Funzioni di aggregazione - DINSTINCT
Quanti capi ci sono in azienda?
SELECT count( distinct reportsTo)
FROM employees;
Funzioni di aggregazione
Quanti pagamenti ho ricevuto?
SELECT count(*)
FROM payments;
Funzioni di aggregazione
Quanti soldi ho ricevuto con i pagamenti?
SELECT SUM(amount)
FROM payments;
Funzioni di aggregazione
Qual è il prezzo medio di vendita di un prodotto?
SELECT avg(MSRP)
FROM products;
Funzioni di aggregazione
Qual è il prezzo medio di vendita di un prodotto? Quale il massimo? Quale il minimo?
SELECT avg(MSRP), max(MSRP), min(MSRP)
FROM products;
Funzioni di aggregazione ERRATE
Attenzione a non chiedere cose assurde
SELECT avg(MSRP), productName
FROM products
- quale productName devo mostrare?
- standard ANSI: errore
- MySql risponde… con il primo valore!
Funzioni di aggregazione e raggruppamenti
Voglio raggruppare le ennuple in sottogruppi in base ad uno o più valori, mostrando anche valori calcolati su ogni gruppo
SELECT a1, a2 , ... , an, aggregatore(ax)
FROM tabella1 WHERE condizioni
GROUP BY a1, a2, ... ,an
Funzioni di aggregazione e raggruppamenti
Mostra gli stati degli ordini e quanti ordini si trovano in ciascuno stato
SELECT status, count(*)
FROM orders
GROUP BY status;
Funzioni di aggregazione e raggruppamenti
Mostra quanti prodotti ho per ogni categoria ed il prezzo medio di vendita
SELECT productLine, count(*), avg(MSRP)
FROM products
GROUP BY productLine;
Aggreghiamo...
Mostrare quanti ordini ho spedito ogni giorno
SELECT count(*), shippedDate
FROM orders
GROUP BY shippedDate
Aggreghiamo...
Mostrare quanti ordini ho spedito nei vari mesi (una riga per mese)
- PostgreSQL: usate
date_part('month', attributo)
SELECT count(*), month(shippedDate)
FROM orders
WHERE shippedDate IS NOT NULL
GROUP BY month(shippedDate);
Aggreghiamo...
Mostrare quanti ordini ho spedito nei vari mesi (una riga per mese ed anno)
- PostgreSQL (mese): usate
date_part('month', attributo) - PostgreSQL (anno): usate
date_part('year', attributo)
SELECT count(*), month(shippedDate),
year(shippedDate)
FROM orders
WHERE shippedDate IS NOT NULL
GROUP BY year(shippedDate), month(shippedDate);
Aggreghiamo…
Mostrare per ogni ordine: il nome del cliente, la data dell’ordine ed il totale dell’ordine
Un passo alla volta:
- calcoliamo il totale di ogni ordine
- estraiamo i dati dalle altre tabelle
Aggreghiamo...
Mostrare per ogni ordine: il totale dell’ordine
SELECT orderNumber,
sum(quantityOrdered*priceEach)
FROM orderdetails
GROUP BY orderNumber;
Aggreghiamo...
Mostrare per ogni ordine: il nome del cliente, la data dell’ordine ed il totale dell’ordine
SELECT customerName, orderDate,
sum(quantityOrdered*priceEach)
FROM orderdetails
INNER JOIN orders USING (orderNumber)
INNER JOIN customers USING (customerNumber)
GROUP BY orderNumber;
Aggreghiamo...
Mostrare quanti ordini ha fatto ogni cliente, mettendo in cima quelli più assidui
SELECT count(*) nOrdini, customerNumber
FROM orders
GROUP BY customerNumber
ORDER BY nOrdini DESC;
Aggreghiamo…
Mostrare l’estratto conto del cliente 124
- pagamenti cliente: importo negativo
- debiti cliente: importo positivo
Un passo alla volta:
- estrarre i pagamenti fatti con la relativa data
- prendere i totali degli ordini del cliente
- unire i due risultati, ordinandoli per data
Aggreghiamo...
Mostrare l’estratto conto del cliente 124
estrarre i pagamenti fatti con la relativa data
SELECT amount*-1, paymentDate FROM payments
WHERE customerNumber = 124
SELECT amount*-1, paymentDate FROM payments
WHERE customerNumber = 124
Aggreghiamo...
Mostrare l’estratto conto del cliente 124
prendere i totali degli ordini del cliente
SELECT sum(quantityOrdered*priceEach),orderDate
FROM orderdetails INNER JOIN orders
USING (orderNumber)
WHERE customerNumber = 124
GROUP BY orderNumber;
SELECT sum(quantityOrdered*priceEach),orderDate
FROM orderdetails INNER JOIN orders
USING (orderNumber)
WHERE customerNumber = 124
GROUP BY orderNumber;
Aggreghiamo...
Mostrare l’estratto conto del cliente 124
unire i due risultati, ordinandoli per data
SELECT amount*-1, paymentDate FROM payments
WHERE customerNumber = 124
UNION
SELECT sum(quantityOrdered*priceEach),orderDate
FROM orderdetails INNER JOIN orders
USING (orderNumber)
WHERE customerNumber = 124
GROUP BY orderNumber
ORDER BY paymentDate;
SELECT amount*-1, paymentDate FROM payments
WHERE customerNumber = 124
UNION
SELECT sum(quantityOrdered*priceEach),orderDate
FROM orderdetails INNER JOIN orders
USING (orderNumber)
WHERE customerNumber = 124
GROUP BY orderNumber
ORDER BY paymentDate;
Filtrare dati aggregati
Come applicare un filtro al risultato di una funzione di aggregazione?
SELECT a1, a2, ... ,an, aggregatore(ax)
FROM tabella1 WHERE condizioni
GROUP BY a1, a2, ... ,an
HAVING condizioniAggregate
Filtrare dati aggregati
Mostrare tutti gli ordini il cui totale è < 10.000
SELECT orderNumber,
sum(quantityOrdered*priceEach) as tot
FROM orderdetails
GROUP BY orderNumber
HAVING tot < 10000;
Filtrare dati aggregati
Mostrare tutti gli ordini il cui totale è < 10.000 e per i quali verranno spediti più di 100 pezzi
SELECT orderNumber,
sum(quantityOrdered) as q,
sum(quantityOrdered*priceEach) as tot
FROM orderdetails
GROUP BY orderNumber
HAVING tot < 10000 AND q > 100;
Filtrare dati aggregati
Mostrare tutti gli ordini il cui totale è < 10.000 e che non sono stati spediti
Hint: ordini spediti hanno status "Shipped"
SELECT ordernumber, status,
SUM(quantityOrdered*priceeach) total
FROM orderdetails
INNER JOIN orders USING(ordernumber)
GROUP BY ordernumber
HAVING status <> 'Shipped' AND total < 10000;
Filtrare dati aggregati
SELECT ordernumber, status,
SUM(quantityOrdered*priceeach) total
FROM orderdetails
INNER JOIN orders USING(ordernumber)
GROUP BY ordernumber
HAVING status <> 'Shipped' AND total < 10000;
forma equivalente
SELECT ordernumber, status,
SUM(quantityOrdered*priceeach) total
FROM orderdetails
INNER JOIN orders USING(ordernumber)
WHERE status <> 'Shipped'
GROUP BY ordernumber
HAVING total < 10000;
Subquery
Posso annidiare le query una dentro l’altra
SELECT a1,a2,...,an,(QUERY singolo val.)
FROM (QUERY)
WHERE a1 > (QUERY singolo val.)
AND a2 IN (QUERY singolo attrib.)
Per adesso:
- le subquery vivono di vita propria
- possiamo scriverle separatamente, poi incorporarle
Subquery - singolo valore
Mostrare per ogni articolo il prezzo di vendita ed il prezzo del prodotto più caro
Hint: subquery nella clausola SELECT
SELECT productName, MSRP,
(SELECT max(MSRP)
FROM products) as massimo
FROM products;
Subquery - singolo valore
Mostrare i dati del pagamento più alto ricevuto
Hint: subquery nella clausola WHERE
SELECT customerNumber, checkNumber, amount
FROM payments
WHERE amount =
(SELECT MAX(amount)
FROM payments);
Subquery - singolo valore
Mostra i pagamenti superiori alla media
SELECT customerNumber, checkNumber, amount
FROM payments
WHERE amount >
(SELECT AVG(amount)
FROM payments);
Subquery - singolo valore
Mostrare i clienti che non hanno fatto ordini
Hint: subquery nella clausola WHERE ... NOT IN
SELECT customername
FROM customers
WHERE customerNumber NOT IN
(SELECT DISTINCT customernumber
FROM orders);
Subquery - singolo attributo
Mostrare i clienti che non hanno fatto ordini
SELECT customername
FROM customers
WHERE customerNumber NOT IN
(SELECT DISTINCT customernumber
FROM orders);
forma equivalente
SELECT customername
FROM customers
LEFT JOIN orders USING (customerNumber)
WHERE orderNumber IS NULL;
Subquery - FROM
Mostrare il numero massimo, minimo e medio di pezzi inseriti negli ordini
Hint: creare prima la query che somma le righe dell’ordine
SELECT max(items), min(items),
floor(avg(items)) as media
FROM (SELECT orderNumber,
SUM(quantityOrdered) AS items
FROM orderdetails
GROUP BY orderNumber) AS lineitems;
Subquery Correlate
Finora:
- posso eseguire la subquery da sola
- il motore la esegue una volta
- … non è sempre così
Subquery Correlate
SELECT a1,a2,...,an
FROM tab1 WHERE
a1 > (SELECT c1
FROM tab2
WHERE tab2.c2 > tab1.a1)
- non eseguibile “da sola”
- eseguita per ogni riga della query principale
- visibilità varaibili: solo da query a subquery
Subquery Correlate
Mostrare i prodotti il cui prezzo di acquisto è superiore alla media della linea cui afferiscono
SELECT productname, buyprice
FROM products AS p
WHERE buyprice > (
SELECT AVG(buyprice)
FROM products
WHERE productline = p.productline);
EXISTS
Operatore booleano (per WHERE): ritorna vero se una sottoquery ha valori
SELECT a1,a2,...,an
FROM tab
WHERE EXISTS (QUERY singolo val.)
Limiti
Non voglio tutte le righe che soddisfano il filtro, solo le TOP N
SELECT a1,a2,...,an
FROM tab
WHERE ...
LIMIT numero
Subquery Correlate
Mostrare i primi 5 clienti (codice cliente, nome e limite di credito)
SELECT customernumber,
customername,
creditlimit
FROM customers
LIMIT 5;
Subquery Correlate
Mostrare i 5 clienti con il credito più elevato
SELECT customernumber, customername,
creditlimit
FROM customers
ORDER BY creditlimit DESC
LIMIT 5;
Limiti
Non voglio tutte le righe che soddisfano il filtro: solo le prime N a partire dalla riga X.
SELECT a1,a2,...,an
FROM tab
WHERE ...
LIMIT X, N
- X → dalla riga Xesima dei risultati (si parte da 0)
- N → quante righe prendere
Limiti
Mostrare il secondo prodotto più costoso (buyprice) in listino
SELECT productName, buyprice
FROM products
ORDER BY buyprice DESC
LIMIT 1, 1;
Aggiungere dati
Como possono inserire una nuova $n$-upla?
INSERT INTO tabella(col1, col2, ...)
VALUES (valore1, valore2, ...)
[, (valore1, valore2, ...), ...]
- se imposto TUTTI gli attributi della tabella, posso omettere i nomi delle colonne (col1, col2,…)
- attributi
AUTO_INCREMENT: NULL
Aggiungere dati
Inserire un nuovo ufficio a Trieste
Hint: INSERT INTO tabella (col1,col2,...) VALUES (valore1,valore2,...)
INSERT INTO offices
VALUES (8, 'Trieste', '+30 040558555',
'Via Valerio 10', null, null,
'Italy', '34100', 'EMEA')
Aggiungere dati e subquery
Vorrei usare una subquery per alimentare l’inserimento dei dati
INSERT INTO tabella(col1, col2, ...)
SELECT ...
Il risultato della SELECT deve fornire:
- lo stesso numero di attributi della tabella di destinazione
- attributi dello stesso dominio di destinazione
Aggiungere dati
Duplicare l’ordine 10425
- creare l’ordine 10426 (a mano, tabella orders)
- prendere tutte le righe di 10425 (orderdetails)
- inserire tutte queste $n$-uple nella tabella (orderdetails)
Aggiungere dati
Duplicare l'ordine 10425
creare l’ordine 10426 (a mano, tabella orders)
Hint: INSERT INTO tabella (col1,col2,...) VALUES (valore1,valore2,...)
INSERT INTO orders
VALUES (10426, '2014-11-11',
'2014-11-30', null,
'In Process',
'Duplica 10425', 119);
Aggiungere dati
Duplicare l'ordine 10425
prendere tutte le righe di 10425 (orderdetails)
Hint: conta l'ordine delle colonne, vi servirà FK 10426
SELECT 10426 AS numero, productCode,
quantityordered, priceEach,
orderLineNumber
FROM orderdetails
WHERE orderNumber = 10425;
Aggiungere dati
Duplicare l'ordine 10425
inserire tutte queste $n$-uple nella tabella (orderdetails)
Hint: INSERT INTO tabella (col1,col2,...) SELECT ...
INSERT INTO orderdetails
SELECT 10426 AS numero, productCode,
quantityordered, priceEach,
orderLineNumber
FROM orderdetails
WHERE orderNumber=10425;
Modificare dati
Come posso modificare $n$-uple esistenti?
UPDATE tabella
SET col1 = valore1
[, col2 = val2...]
[WHERE condizione]
- ogni campo può assumere un valore esplicito, o il risultato di una funzione, sottoquery, ecc…
- se non uso la clausola
WHERE, aggiorno tutte le $n$-uple della tabella
Modificare dati
Cambiare indirizzo email a Mary Patterson
Impiegato 1056, mettete una email a scelta
Hint: UPDATE tabella SET col1 = valore1 WHERE condizione
UPDATE employees
SET email = 'mary.patterson@classicmodelcars.com'
WHERE employeeNumber = 1056;
Modificare dati
Cambiare prezzo di acquisto e vendita della '2001 Ferrari Enzo'
Hint: UPDATE tabella SET col1 = valore1 WHERE condizione
UPDATE products
SET msrp = 500, buyprice = 200
WHERE productName = '2001 Ferrari Enzo';
Modificare dati
Aumentare del 5% tutti i prezzi di vendita
Hint: UPDATE tabella SET col1 = valore1 WHERE condizione
UPDATE products
SET msrp = msrp*1.05;
Modificare dati
Associare ai clienti senza venditore l’agente con matricola più alta (appena arrivato)
- individuare i clienti senza venditore
- trovare l’agente con matricola più alta
- aggiornare i dati
Modificare dati
Associare ai clienti senza venditore l’agente con matricola più alta
Individuare i clienti senza venditore
SELECT customerNumber
FROM customers
WHERE salesRepEmployeeNumber IS NULL;
Modificare dati
Associare ai clienti senza venditore l’agente con matricola più alta
Trovare l'agente con matricola più alta
Hint: venditore ha `jobTitle = 'Sales Rep'`
SELECT max(employeeNumber)
FROM employees
WHERE jobTitle = 'Sales Rep';
Modificare dati
Associare ai clienti senza venditore l’agente con matricola più alta
Aggiornare i dati
UPDATE customers
SET salesRepEmployeeNumber =
(SELECT max(employeeNumber)
FROM employees
WHERE jobTitle = 'Sales Rep')
WHERE salesRepEmployeeNumber IS NULL;
Attenzione
UPDATE tabella
SET col1 = col1 +1, col2 = col1
- MySql: la seconda operazione è fatta con il valore aggiornato di
col1 - SQL standard: la seconda operazione è fatta con il valore originale di
col1
Eliminare dati
Come posso eliminare dati dalla tabella?
DELETE FROM tabella
[WHERE condizioni]
oppure
DELETE FROM tabella
[WHERE condizioni]
once and for all:
- non si torna indietro
- prima di eseguire la query, provare a metterci una
SELECT *per vedere che succede
Eliminare dati
Eliminare tutti i clienti italiani
Hint: DELETE FROM tab WHERE ...
DELETE FROM customers
WHERE country = "Italy";
Eliminare dati
Perchè non funziona?
Opzioni di MySql WorkBench:
Error Code: 1175. You are using safe update
mode and you tried to update a table without
a WHERE that uses a KEY column To disable
safe mode, toggle the option in Preferences ->
SQL Queries and reconnect.
Eliminare dati
Perchè non funziona?
Vincoli interrelazionali:
Error executing SQL statement.
ERROR: update or delete on table "customers" violates foreign key constraint "orders_ibfk_1" on table "orders"
Dettaglio: Key (customernumber)=(249) is still referenced from table "orders". - Connection: PostgreSQL: 2ms
Devo prima modificare le altre tabelle!
Check
Permette di introdurre vincoli di integrità generici
CREATE TABLE nomeTab(
attr1 tipo1 CHECK (condizione),
attr2 tipo2,...,
CHECK (condizione))
- le condizioni sono espressioni booleane
- possono essere complesse (es: subquery)
- non funzionano in MySql
CHECK
- il sesso può essere solo M o F
stipendio inferiore a quello del capo
CREATE TABLE Impiegato( matricola integer, cognome character(20), sesso character NOT NULL CHECK (sesso in (‘M’,‘F’)), stipendio integer, superiore integer, CHECK (stipendio <= (SELECT stipendio FROM Impiegato J WHERE superiore = J.matricola))
ASSERTION
Permettono di introdurre vincoli di integrità a livello di schema
CREATE ASSERTION nome CHECK (condizione)
Stesse note del check
ASSERTION
La tabella impiegato deve avere almeno un nominativo
CREATE ASSERTION AlmenoUnImpiegato
CHECK ((SELECT count(*) FROM Impiegato) >= 1)
Variabili
Posso definire variabili da usare nelle query
SET @variabile = valore;
SELECT @variabile;
- vivono e muoiono nella sessione
- il valore può essere anche una query che ritorna un solo dato
- MySQL: case insensitive, solo tipi semplici (integer, decimal, string, …)
Variabili
Creare una variabile di nome “pippo”, assegnarci il valore “Hello Word!” e mostrarne in contenuto
SET @pippo = 'Hello, World!';
SELECT @pippo;
Variabili
Salvare nella variabile “prezzo” il prezzo più alto (MSRP) presente a listino e mostrarne il valore
SET @prezzo = (SELECT max(msrp)
FROM products);
SELECT @prezzo;
Variabili
Mostrare i prodotti in cui il valore MSRP è pari alla variabile appena impostata
SELET * FROM products
WHERE MSRP = @prezzo;
Esecuzione query
Cosa accade quando invio una query al server?
- Parser: trasforma il testo in un albero di comandi
- PreProcessor: la sintassi è corretta?
- Security: l’utente può fare questo?
- Optimizer: posso riscrivere la query in modo più intelligente?
- Execution Engine: effettua l’operazione
- Trasmissione Dati
E se devo eseguire spesso la stessa query??
Profiling (MySQL)
Cosa fa il motore?
SET profiling = 1;
esecuzione comandi
SHOW PROFILES;
SHOW PROFILE [FOR QUERY n];
SET profiling = 0;
SHOW PROFILES: storico dei tempi di esecuzioneSHOW PROFILE: come ho impiegato il tempo nell’ultima query/query specificata?
Profiling
Cosa posso vedere?
Tipo
ALL: tutte le informazioniCPU: tempo CPU per user/systemSWAPS: utilizzo della memoria su discoSOURCE: nome della funzione/libreria usati
Privilegi
Mostra tutti i dati dell’ultima query
SHOW PROFILE ALL FOR QUERY 4;
Prepared statement
Posso precompilare le query che uso più spesso
PREPARE nomeStatement FROM 'query';
EXECUTE nomeStatement USING p1, p2,...;
DEALLOCATE PREPARE nomeStatement;
PREPARE: crea una query riutilizzabile, che può ricevere parametriEXECUTE: esegue il comando salvatoDEALLOCATE PREPARE: elimina il comando- vivono e muoiono nella sessione
Prepared Statement: PREPARE
Creare lo statement (MySQL)
PREPARE nomeStatement FROM
'SELECT a1,a2,...
FROM tabella
WHERE a1 = ? AND a2 = ?';
- la query da eseguire è passata come stringa
- ogni “?”” corrisponde ad un parametro che verrà comunicato in sede di esecuzione
Prepared Statement: PREPARE
Creare lo statement (PostgreSQL)
PREPARE nomeStatement(type1, type2, ...) AS
SELECT a1,a2,...
FROM tabella
WHERE a1 = $1 AND a2 = $2;
- specifico i tipi tra parentesi
- si fa riferimento ai paramentri tramite
$
Prepared Statement: PREPARE
Creare lo statement “stmt1” il quale seleziona productCode e productName dal listino mostrando solo le ennuple con MSRP maggiore del parametro che verrà fornito.
Hint: DPREPARE nomeStatement FROM 'SELECT a1,a2,... FROM tabella WHERE a1 = ? AND a2 = ?';
PREPARE stmt1 FROM
'SELECT productCode, productName
FROM products WHERE MSRP > ?';
Prepared Statement: EXECUTE
Eseguire lo statement (MySQL)
EXECUTE nomeStatement
[USING @var1, @var2,...];
- i parametri devono essere variabili
- in teoria sono opzionali (posso creare statement senza parametri, ma è meglio evitarlo)
Prepared Statement: EXECUTE
Eseguire lo statement (PostgreSQL)
EXECUTE nomeStatement(arg1, arg2, ...);
Prepared Statement: PREPARE
Usando stmt1 mostrare i prodotti con prezzo superiore ai 100$
Hint: EXECUTE nomeStatement
[USING @var1, @var2,...];
SET @MSRP = 100;
EXECUTE stmt1 USING @MSRP;
Prepared Statement: DEALLOCATE
Eliminare lo statement
DEALLOCATE PREPARE nomeStatement;
DROP PREPARE nomeStatement;
Schema esterno
Schema Esterno
Creare uno schema esterno che mostri il listino ai clienti (codice e nome prodotto, MSRP).
PREPARE stmtListinoClienti FROM
'SELECT productCode, productName, MSRP FROM products';
Problemi:
- codice inserito nell’applicazione
- sparisce quando chiudo la connessione
- va creato per ogni connessione
- accesso diverso da una normale tabella
Viste
Rappresentazione alternativa dei dati
- SQL SELECT salvata nel motore
- persistente: non muore alla chiusura della connessione
- posso usare query per interrogarla
- posso aggiornare i dati (con dei limiti)
Viste
Vantaggi
- semplificare query complesse
- nascondere dati sensibili
- gestire gli accessi
- campi calcolati appiono come colonne normali
- compatibilità
Viste
Svantaggi
- se modifico le tabelle, devo aggiornare le viste
- non accetta parametri
- non è compilata
- performance leggermente peggiori (in particolare se uso viste che contengono altre viste)
Viste
Come funzionano? [MySQL]
MERGE (predefinito)
- nella query inserisco il codice contenuto nella vista
- eseguo il codice ottenuto
Viste
Come funzionano? [MySQL]
TEMPTABLE (materialized)
- creo una tabella temporanea in cui salvo il risultato
- obbligatoria se la vista non ha una relazione biunivoca con la tabella sottostante:
- funzioni di aggregazione, group by, having
- distinct, limit
- union
- subquery nella lista degli attributi
Viste
Definizione di una vista
CREATE VIEW nomeVista AS
SELECT ...
Dettagli:
- la SELECT può essere eseguita da sola
- posso usare subquery nella clausola WHERE
- non posso usarle nella clausola FROM
Viste
Creare uno schema esterno “viewListinoClienti” che mostri il listino per i clienti (codice e nome prodotto, MSRP), quindi mostrarne i dati
CREATE VIEW viewListinoClienti AS
SELECT productCode, productName, MSRP
FROM products;
SELECT * from viewListinoClienti;
Viste
Creare uno schema esterno “viewTotaleOrdini” che mostri il numero dell’ordine e l’importo totale
Hint: CREATE VIEW nomeVista AS
SELECT ...
CREATE VIEW viewTotaleOrdini AS
SELECT orderNumber,
SUM(quantityOrdered * priceEach) total
FROM orderdetails
GROUP by orderNumber
Viste
Usando “viewTotaleOrdini” mostrare il totale dell’ordine 10102
SELECT total
FROM viewTotaleOrdini
WHERE orderNumber = 10102;
Viste
Cosa fa una vista?
SHOW CREATE VIEW nomeVista;
Eliminare una vista
DROP VIEW nomeVista;
Viste
Modificare una vista
ALTER VIEW nomeVista AS nuovaSELECT;
Viste modificabili
Posso modificare i dati di una vista se la SELECT:
- è riferita ad una sola tabella
- non contiene GROUP BY o HAVING
- non contiene DISTINCT
- non fa riferimento a viste non modificabili
- la selezione non contiene espressioni
Viste Modificabili
Creare la vista “officeInfo” mostrando codice ufficio, telefono e città degli uffici. Provare a modificare qualche dato (es: n. tel.)
CREATE VIEW officeInfo
AS SELECT officeCode, phone, city
FROM offices;
UPDATE officeInfo
SET phone = '+39 040 55558555'
WHERE officeCode = 4;
Controllo Accessi
Connessione
- utente e password valide?
- [connessione da client autorizzato]?
Controllo Accessi
Richiesta
- l’utente connesso può fare questa operazione?
- può accedere a questo DB?
- può accedete a questa tabella?
- può accedete a questo attributo?
- può eseguire questa procedura?
Aggiungere utenti
Dipende dal motore
MySQL:
CREATE USER nome@host
IDENTIFIED BY 'password'
Oracle:
CREATE USER nome
IDENTIFIED BY password
SQL Server
CREATE USER nome
WITH PASSWORD = 'password'
Aggiungere utenti
Dettagli per MySQL:
- posso usare wildards nell’host se le racchiudo tra apici -
'%'per ogni host 'nome@host'crea un utente con usernamenome@hostlegato all’host%FLUSH PRIVILEGESforza il reload dei dati
Aggiungere Utenti
Creare l’utente “pippo” con password “pluto” che possa connettersi solo dal vostro computer
CREATE USER pippo@localhost
IDENTIFIED BY 'pluto';
Controllo accessi
12 regole di Codd
- INFORMAZIONI: tutte le informazioni in un DBR sono rappresentate esplicitamente da valori in tabelle (DEFINIZIONE)
Controllo Accessi - MySQL
Connessione
- Utente e password valide?
- Connessione da un client autorizzato?
DataBase mysql
Tabella
userINSERT INTO user(host,user,password) VALUES('localhost','pippo', PASSWORD('pluto')); FLUSH PRIVILEGES;
Modificare gli utenti
Cambiare la password
SET PASSWORD FOR user@host =
PASSWORD('Secret1970');
Eliminare un utente
DROP USER user@host;
Assegnare i permessi
Un utente appena creato non può fare nulla
GRANT privilegio (colonne)
ON risorsa
TO account
[WITH GRANT OPTION]
privilegio: tipo di operazione permessacolonne: se si applica solo ad alcune colonnerisorsa: database.tabella — wildcard: *account: utente@hostWITH GRANT OPTION: l’utente può propagare i permessi ad altri
Privilegi
ALL: tuttiALTER: modificare tabellaCREATE: creare oggettiDELETE: eliminare ennupleSELECT: leggere i datiUPDATE: modificare i dati- … e tanti altri
Privilegi
Permettere all’utente pippo di leggere, modificare e cancellare dati al DB dei modellini.
Hint: GRANT privilegio (colonne)
ON risorsa
TO account
GRANT SELECT, UPDATE, DELETE ON
classicmodels.* TO 'pippo'@'%';
Privilegi
Creare un altro amministratore
GRANT ALL ON *.* TO 'super'@'localhost'
WITH GRANT OPTION;
Permettere ad un utente di leggere e modificare i numeri di telefono dei clienti e di vederne i nomi
GRANT SELECT (phone, customerName),
UPDATE (phone)
ON classicmodels.customers
TO 'someuser'@'somehost';
Visualizzare i permessi
Posso vedere i privilegi di ogni utente
SHOW GRANTS FOR utente;
Revocare i permessi
Sintassi molto simile a GRANT
REVOKE privilege_type [(column_list)]
[, priv_type [(column_list)]]...
ON [object_type] privilege_level
FROM user [, user]...
Revocare i permessi
REVOKE UPDATE, DELETE ON
classicmodels.* FROM
'rfc'@'localhost';
Transazioni
Insieme di operazioni da considerare indivisibile (“atomico”), corretto anche in presenza di concorrenza e con effetti definitivi
ACID
Proprietà transazioni:
- Atomicità
- Consistenza
- Isolamento
- Durabilità (persistenza)
Atomicità
La sequenza di operazioni sulla base di dati viene eseguita per intero o per niente.
Esempio: trasferimento di fondi da un conto A ad un conto B: o si fanno il prelevamento da A e il versamento su B o nessuno dei due
Consistenza
Al termine dell’esecuzione di una transazione, i vincoli di integrità debbono essere soddisfatti
Durante l’esecuzione ci possono essere violazioni, ma se restano alla fine allora la transazione deve essere annullata per intero (“abortita”)
Isolamento
L’effetto di transazioni concorrenti deve essere coerente (ad esempio equivalente all’esecuzione separata)
Esempio: se due assegni emessi sullo stesso conto corrente vengono incassati contemporaneamente si deve evitare di trascurarne uno
Durabilità
La conclusione positiva di una transazione corrisponde ad un impegno (“commit”) a mantenere traccia del risultato in modo definitivo, anche in presenza di guasti e di esecuzione concorrente
Transazioni
La sintassi dipende dal motore
In MySQL:
START TRANSACTION: specifica l’inizio della transazione (le operazioni non vengono eseguite sulla base di dati)COMMIT: le operazioni specificate a partire dal begin transaction vengono eseguiteROLLBACK: si rinuncia all’esecuzione delle operazioni specificate dopo l’ultimo begin transaction
Transazioni
SQL Server
BEGIN TRANSACTIONCOMMIT WORKROLLBACK WORK
Esempio Transazione
start transaction;
select @orderNumber := max(orderNUmber) from orders;
set @orderNumber = @orderNumber + 1;
insert into orders(orderNumber, orderDate, requiredDate, shippedDate, status, customerNumber)
values(@orderNumber, now(), date_add(now(), INTERVAL 5 DAY),
date_add(now(), INTERVAL 2 DAY), 'In Process', 145);
insert into orderdetails(orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
values(@orderNumber,'S18_1749', 30, '136', 1),
(@orderNumber,'S18_2248', 50, '55.09', 2);
commit;
Transazioni in un DBMS
Due moduli fondamentali:
- gestore della concorrenza
- garantisce isolamento e consistenza
- scheduler delle operazioni
- gestore dell’affidabilità
- garantisce atomicità e durevolezza
- consentire il recupero in caso di guasti
Gestore dell’affidabilità
Idee di base:
- registrare tutte le azioni eseguite in un file di registro (“log”)
- se si rompe qualcosa durante la transazione, so come tornare indietro
Attenzione:
Qualcosa è sempre in memoria e può sempre essere perso
Log delle transazioni
Come salvo le transazioni?
- Write Ahead Logging:
- il log contiene i blocchi modificati
- commit = copiare i dati dal log al file del DB
- scelto da quasi tutti i motori
- Command Logging:
- il log contiene lo storico delle istruzioni
- commit = eseguire realmente le operazioni
Redo Logging
Soluzione di MySQL (Write Ahead)
- salvo i dati in un log che risiede in memoria
- sposto piccole porzioni in un log su disco
- ogni tanto unisco il log su disco ai dati reali
SQL
Programming Language (PL)
Oggetti programmabili in SQL
È possibile racchiudere comandi SQL in oggetti programmabili la cui definizione rimane nelle tabelle di sistema:
- facilitano il riutilizzo del piano di esecuzione (precompilate)
- incapsulano la logica applicativa di accesso ai dati
- nascondono al client la complessità della base dati
Oggetti programmabili in SQL
Viste
Stored Procedure
insieme di comandi SQL con parametri di input e output che possono restituire recordset
Oggetti programmabili in SQL
Trigger
particolari stored procedure che vengono associate ad una operazione su un oggetto e invocate automaticamente
User Defined Function
consentono di raggruppare e riutilizzare codice SQL solitamente ripetuto all’interno di SP e trigger
Assemblies SQLCLR
semplificando: stored procedure scritte in linguaggi Microsoft
Stored Procedure
Subroutine che contengono tutto il codice necessario per effettuare una operazione
- incapsulano task ripetitivi
- codice ammesso: tutto (DDL, DML, TSQL,…)
- accettano parametri di input
- producono zero, uno o più output
- parametri di output
- resultset
Stored Procedure
FONDAMENTALI per incapsulare la logica di
- accesso alle tabelle
- manipolazione dei dati
Stored Procedure
Permettono la creazione di un livello di astrazione del modello fisico del database
- aiutano a mantenere un alto disaccoppiamento
- garantiscono la possibilità di intervenire sul database senza necessariamente modificare le applicazioni che lo usano
- introduzione di nuove funzionalità necessarie ad altre applicazioni (un db non è privato)
- miglioramento performance
Stored Procedure: vantaggi
- mascherano lo schema logico del DB
- riutilizzo del codice
- permettono l’implementazione di arbitrari meccanismi di sicurezza
- migliorano le performance (cached execution plans)
- MySql: ricompilata per ogni connessione
- riducono il traffico di rete
Stored Procedure: svantaggi
- aumentano il carico (CPU, memoria) del DBMS
- difficile farne il debug
- MySql: non possibile
- sintassi particolare
- non sono transazionali di per se
- …ma possono diventarlo usanto T-SQL
Creare Stored Procedure
Anche qui dipende dal motore…
CREATE PROCEDURE nome()
BEGIN
... codice
END
MS SQL Server:
CREATE PROCEDURE nome
AS [BEGIN]
... codice
[END]
Creare Stored Procedure
Creare una SP che prenda tutti i dati dei prodotti
CREATE PROCEDURE sp_getAllProducts()
BEGIN
SELECT * FROM products;
END
Problema: potrei avere più istruzioni, e non voglio che il DBMS le interpreti una alla volta (ogni volta che trova un “;”)
Creare Stored Procedure
MySql: cambio il delimitatore
DELIMITER $$
CREATE PROCEDURE nome()
BEGIN
... codice1;
... codice2;
END $$
DELIMITER ;
Creare Stored Procedure
SQL Server: GO!
CREATE PROCEDURE nome
AS [BEGIN]
... codice1;
... codice2;
[END]
GO
Eseguire Stored Procedure
Dipende dal motore
MySql
CALL nomeStoredProcedure()
SQL Server
EXEC nomeStoredProcedure
PostgreSQL
SELECT nomeStoredProcedure()
Oracle
EXECUTE nomeStoredProcedure()
Stored Procedure
Creare una SP che mostri i dati di tutti i dipendenti che siano "SalesRep"
Hint: CREATE PROCEDURE nome()
BEGIN
... codice
END
DELIMITER $$
CREATE PROCEDURE sp_getSalesRep()
BEGIN
SELECT * FROM employees
WHERE jobTitle = 'Sales Rep';
END
Visualizzare le Stored Procedure
Per vedere tutte le SP nel motore:
SHOW PROCEDURE STATUS
[WHERE condizioni]
Condizioni:
db: nome del DBname: nome della SP- posso usare uguaglianza,
LIKE,OR,AND, …
Visualizzare ed eliminare SP
Per vedere il codice di una SP:
SHOW CREATE PROCEDURE spNome
Per eliminare una SP:
DROP PROCEDURE spNome
Modificare Stored Procedure
Dipende dal motore.
MySql
DROP + CREATE
SQL Server
ALTER nomeStoredProcedure
AS
...codice
GO
Parametri
Una Stored Procedure può ricevere dei parametri:
CREATE PROCEDURE nomeSP(
nomePar1 tipoPar1,
nomePar2 tipoPar2, ...
)
BEGIN
... codice
END
CALL nomeSP(par1, par2,...)
Parametri
Creare una SP che mostri i dati di tutti i dipendenti che siano della tipologia passata come parametro (Principal, Sales Rep, ecc.)
CREATE PROCEDURE sp_getEmployeeByType(
tipoImp varchar(50))
BEGIN
SELECT * FROM employees WHERE jobTitle = tipoImp;
END
Parametri
I parametri sono passati:
- in sola lettura (solo input) →
IN- è l’opzione di default
- in sola scrittura (solo output) →
OUT- durante l’esecuzione uso variabili
leggibili e scrivibili (bidirezionali) →
INOUTCREATE PROCEDURE nomeSP( direzione nomePar1 tipoPar1, direzione nomePar2 tipoPar2,...) BEGIN ... codice END
Parametri
Creare una SP che funga da contatore
CREATE PROCEDURE sp_conta(
INOUT count INT(4),
IN inc INT(4))
BEGIN
SET count = count + inc;
END
Verifica
SET @counter = 1;
CALL set_counter(@counter,1); -- 2
CALL set_counter(@counter,1); -- 3
CALL set_counter(@counter,5); -- 8
SELECT @counter; -- 8
Parametri
Creare una SP che raddoppi il valore passato
CREATE PROCEDURE sp_raddoppia(
INOUT valore int(11))
BEGIN
SET valore = valore * 2;
END
Verifica
set @val = 10;
select @val;
CALL sp_raddoppia(@val);
select @val;
Parametri
Creare una SP che prenda in input il numero d'ordine e ritorni il numero di oggetti comprati
CREATE PROCEDURE sp_contaOggettiInOrdine(
IN oNumber INT,
OUT numberObjects INT)
BEGIN
SET numberObjects = (
SELECT sum(quantityOrdered) FROM
orderdetails WHERE orderNumber = oNumber
);
END
Verifica
CALL sp_contaOggettiInOrdine(10100, @numObj);
select @numObj; --- 151
SELECT INTO
Se devo scrivere direttamente il risultato di una query in una variabile
CREATE PROCEDURE sp_contaOggettiInOrdine(
IN oNumber INT,
OUT numberObjects INT)
BEGIN
SELECT sum(quantityOrdered)
INTO numberObjects
FROM orderdetails
WHERE orderNumber = oNumber);
END
SELECT INTO
Creare una SP che riceva in input lo status dell'ordine e dica quanti ordini vi sono
CREATE PROCEDURE sp_contaOrdini(
IN orderStatus VARCHAR(25),
OUT total INT)
BEGIN
SELECT count(orderNumber)
INTO total FROM orders
WHERE status = orderStatus;
END
Verifica
CALL sp_contaOrdini('Shipped',@total);
SELECT @total; --- 303
Più istruzioni
Creare una SP che riceva in input il codice cliente e restituisca tanti valori:
- numero ordini spediti (status = Shipped)
- numero ordini cancellati (Canceled)
- numero ordini risolti (Resolved)
- numero ordini confutati (Disputed)
Provate con il cliente 141:
CALL sp_getOrderByCust(141,@shipped,@canceled,
@resolved,@disputed);
SELECT @shipped,@canceled,@resolved,@disputed;
Più istruzioni
DELIMITER $$
CREATE PROCEDURE get_order_by_cust(IN cust_no INT,
OUT shipped INT, OUT canceled INT,
OUT resolved INT, OUT disputed INT)
BEGIN
-- shipped
SELECT count(*) INTO shipped FROM orders
WHERE customerNumber = cust_no AND status = 'Shipped';
-- canceled
SELECT count(*) INTO canceled FROM orders
WHERE customerNumber = cust_no AND status = 'Canceled';
-- resolved
SELECT count(*) INTO resolved FROM orders
WHERE customerNumber = cust_no AND status = 'Resolved';
-- Disputed
SELECT count(*) INTO disputed FROM orders
WHERE customerNumber = cust_no AND status = 'Disputed';
Variabili
MySql
Le variabili hanno tre livelli di visibilità:
- globali (@@): tutti le vedono
- connessione (@): connessione vede le proprie
SET @variabile = 10
- locali (senza @): nascono e muoiono nella SP
DECLARE nomeVariabile tipoVariabileSET nomeVariabile = valore
Condizioni
Nelle Stored Procedure posso inserire IF:
IF espressione THEN
comandi
ELSE IF espressione THEN
comandi
ELSE
comandi
END IF;
Condizioni
Creare una SP che prenda in input il codice cliente e restituisca una stringa che vale:
- PLATINUM se il credito è > 50.000
- GOLD se il credito è > 10.000 e <= 50.000
- SILVER altrimenti
Provate con il cliente 103:
CALL sp_getCustomerLevel(103, @livello);
SELECT @livello;
Condizioni
DELIMITER $$
CREATE PROCEDURE sp_getCustomerLevel(
IN custNo int(11),
OUT customerLevel varchar(10))
BEGIN
DECLARE creditlim double;
SELECT creditlimit INTO creditlim
FROM customers
WHERE customerNumber = custNo;
IF creditlim > 50000 THEN
SET customerLevel = 'PLATINUM';
ELSEIF creditlim >= 10000 THEN
SET customerLevel = 'GOLD';
ELSE
SET customerLevel = 'SILVER';
END IF;
END;
Cicli
Posso ripetere più volte la stessa operazione:
WHILE espressione DO
comandi
END WHILE;
REPEAT
comandi
UNTIL espressione
END REPEAT;
Dettagli:
LEAVE: esce dal cicloITERATE: procede con l’iterazione successiva
Cicli
SP che calcoli la serie di Fibonacci
DELIMITER $$
CREATE PROCEDURE sp_fibonacci(IN n int, OUT out_fib int)
BEGIN
DECLARE m INT default 0;
DECLARE k INT default 1;
DECLARE i INT default 1;
DECLARE tmp INT;
WHILE (i<=n) DO
set tmp = m+k;
set m = k;
set k = tmp;
set i = i+1;
END WHILE;
SET out_fib = m;
END;
Gestire gli errori
Voglio gestire gli errori nella SP
DECLARE azione HANDLER FOR
condizione [BEGIN] codice [END]
condizione: cosa vogliamo intercettarecodice: cosa fareazione: come comportarsi dopo aver eseguito il codiceCONTINUE→ continua con il restoEXIT→ termina l’esecuzione
Gestire gli errori
DECLARE azione HANDLER FOR
condizione [BEGIN] codice [END]
Condizioni:
- codice errore MySql
- Es: 1062, chiave duplicata
- SQLSTATE ‘codiceNumerico’
- Es: 22012, divisione per zero
- SQLWARNING
- NOTFOUND
Gestire gli errori
In caso di errore, annullare la transazione e dare un messaggio
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
ROLLBACK;
SELECT 'Errore: ho annullato tutto!';
END;
Segnalare errori
Posso lanciare messaggi di errore
SIGNAL SQLSTATE 'codice'
SET MESSAGE_TEXT = 'testo'
Codice definito dall’utente: 45000
Segnalare errori
Scrivere una SP che ritorni il numero di ordini di un cliente. Se non esiste, dare un errore
Hint: SIGNAL SQLSTATE 'codice'
SET MESSAGE_TEXT = 'testo'
CREATE PROCEDURE sp_countOrders(customerNo int)
BEGIN
DECLARE conteggio INT;
SELECT count(*) INTO conteggio FROM customers
WHERE customerNumber = customerNo;
IF conteggio = 0 THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Errore generico';
END IF;
SELECT count(*) FROM orders WHERE customerNumber = customerNo;
END
Cursori
Permettono di processare singole righe di un resultset
- Read-only: non posso aggiornare i dati usando il cursore
- Non-scrollable: posso scorrere il dataset senza cambiarne l’ordinamento
- Asensitive: puntano ai dati reali, non ad una copia → rapidi a crearsi, ma modifiche fatte ai dati da altre connessioni si ripercuotono sul cursore
Cursori
Definisco il nome del cursore e la query che userà
DECLARE nomeCursore CURSOR FOR
SELECT ...
Cursori
Apro il cursore, eseguendo la query
OPEN nomeCursore
Cursori
…uso il cursore in un ciclo
FETCH nomeCursore INTO var1, var2, ...
Cursori
Chiudo il cursore (libero memoria):
CLOSE nomeCursore
Cursori

Cursori
Quando smetto di usare il cursore?
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished = 1;
Uso un handler: quando non ho altri dati, si verifica NOT FOUND
Terminerò il ciclo quando finished == 1
Cursori
Creare una SP che ritorni in un singolo valore tutti gli indirizzi email dei dipendenti
Hints:
DECLARE nomeCursore CURSOR FOR SELECT ...OPEN/CLOSE nomeCursoreFETCH nomeCursore INTO var1,var2,...DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished = 1;
Risultato: @emails: mgerard@classicmodelcars.com;ykato@classicmo...
Cursori
Creare una SP che ritorni in un singolo valore tutti gli indirizzi email dei dipendenti
CREATE PROCEDURE sp_buildEmailList (INOUT email_list varchar(4000))
BEGIN
DECLARE finished INTEGER DEFAULT 0;
DECLARE v_email varchar(100) DEFAULT "";
DECLARE email_cursor CURSOR FOR SELECT email FROM employees
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished = 1;
OPEN email_cursor;
WHILE (finished = 0) DO
FETCH email_cursor INTO v_email;
IF finished = 0 THEN
SET email_list = CONCAT(v_email,";",email_list);
END IF;
END WHILE;
CLOSE email_cursor;
END
User Defined Function
- Scalar Functions
- Simile ad una built-in function
- Ritorna un singolo valore costruito con una serie di statements
- Multi-Statement Table-valued Functions
- Contenuto simile ad una stored procedure
- Referenziata come una Vista
- In-line Table-valued Functions
- Simile ad una Vista con parametri
- Ritorna una tabella come risultato di uno statement SELECT singolo
UDF vs SP
- Risultato
- SP: restituisce 0 o N valori
- UDF: restituisce sempre 1 valore
- Parametri
- SP: input/output
- UDF: solo input
- Modifiche
- SP: non può modificare il DB
- UDF: solo SELECT (Myql, Oracle: tutto, ma meglio evitare)
UDF vs SP
- Chi richiama chi
- SP: può richiamare UDF
- UDF: non può richiamare SP
- SELECT
- SP: non può essere usata in una SELECT
- UDF: può essere usata in una SELECT
- RecordSet
- SP: se ritorna una tabella non posso riusarla (no select)
- UDF: posso usarla come una normale tabella
User Defined Function
Come definire una UDF
CREATE FUNCTION function_name
(param1 tipo1,param2 tipo2,...)
RETURNS tipo
[NOT] DETERMINISTIC
BEGIN
statements
END
Si usa come una funzione normale (select, ecc)
Deterministic o no?
Aiuto il motore a capire come ottimizzare
- Deterministic: se l’input e lo stato del DB non variano, l’output non varia
- NON Deterministic: l’output può variare anche se l’input non varia
- now()
- rand()
Deterministic: e se sbaglio?
Il motore si fida
- dico
Deterministicma non lo è: risultati non corretti (l’execution planner può decidere che non occorre ricalcolare) - dico
NON Deterministicma lo è: prestazioni peggiori (ricalcolo anche se non serve)
User Defined Function
Creare una UDF che riceve in input un numero e ne restituisca il doppio, ed usarla in una query
Hint: CREATE FUNCTION function_name
(param1 tipo1,param2 tipo2,...)
RETURNS tipo [NOT] DETERMINISTIC
BEGIN
statements
END
CREATE FUNCTION udf_raddoppia (numero int)
RETURNS INT DETERMINISTIC
BEGIN
RETURN numero * 2;
END
User Defined Function
Creare una UDF che riceva il credito del cliente e restituisca il livello (platinum, ... )
CREATE FUNCTION udf_customerLevel
(p_creditLimit double)
RETURNS VARCHAR(10) DETERMINISTIC
BEGIN
DECLARE lvl varchar(10);
IF p_creditLimit > 50000 THEN
SET lvl = 'PLATINUM';
ELSEIF p_creditLimit >= 10000 THEN
SET lvl = 'GOLD';
ELSE
SET lvl = 'SILVER';
END IF;
RETURN (lvl);
END
User Defined Function
Creare una UDF che riceva il codice cliente e restituisca il numero di ordini che ha fatto.
CREATE FUNCTION udf_contaOrdini(cliente int)
RETURNS INT(11)
BEGIN
DECLARE conteggio INT;
SELECT count(*) INTO conteggio FROM orders
WHERE customerNumber = cliente;
RETURN conteggio;
END
Trigger
Operazioni da eseguire quando si verifica un certo evento
- non viene richiamata direttamente
- parte automaticamente quando si effettua una operazione su una certa tabella (insert, delete, update)
- possono essere legati ad eventi temporali
- limiti MySQL: non possono usare UDF, SP, prepared statements
Trigger
VANTAGGI
- ulteriore controllo dell’integrità dei dati
- controlli non possibili per limiti del motore (es: CHECK in MySql)
- controlli aggiuntivi sulla logica del programma
- molto comodi per l’audit (registrazione) delle modifiche
Trigger
Creazione di un trigger
CREATE TRIGGER nome quando
ON nomeTabella
FOR EACH ROW
BEGIN
codice
END
- ogni trigger ha un nome
- ogni trigger è riferito ad una tabella
Trigger: quando
Tralasciamo i trigger temporali
Che operazione controlliamo?
INSERT,UPDATEoDELETE
Quando devo eseguire il trigger?
BEFORE- es: i dati sono coretti?
AFTER- registro chi ha modificato i dati, ricalcolo valori
ES: BEFORE UPDATE
Trigger: granularità
Statement level (default SQL Server)
- il trigger viene eseguito una volta sola per ogni comando che lo ha attivato, indipendentemente dal numero di tuple modificate
- è il modo più vicino all’approccio tradizionale dei comandi SQL, che sono di norma set-oriented
Trigger: granularità
Row level
- FOR EACH ROW, unico per MySQL
- il trigger viene eseguito una volta per ciascuna tupla che è stata modificata dal comando
- consente di scrivere i trigger in modo più semplice
- può essere meno efficiente
Trigger: OLD & NEW
Permettono di distinguere il record prima e dopo la modifica
- OLD: valore precedente
- usabile nel DELETE
- usabile nel BEFORE UPDATE
- NEW: valore dopo le modifiche
- usabile nell’INSERT
- usabile nel BEFORE UPDATE
Es: OLD.contactLastName
Creiamo una tabella di AUDIT
CREATE TABLE employees_audit (
id int(11) NOT NULL AUTO_INCREMENT,
employeeNumber int(11) NOT NULL,
lastname varchar(50) NOT NULL,
changedon datetime DEFAULT NULL,
changedBy varchar(50) DEFAULT NULL,
action varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
)
Trigger che registra le modifiche
DELIMITER $$
CREATE TRIGGER trg_beforeUpdateEmployees
BEFORE UPDATE ON employees
FOR EACH ROW
BEGIN
INSERT INTO employees_audit
SET action = 'update',
employeeNumber = OLD.employeeNumber,
lastname = OLD.lastname,
changedon = NOW(),
changedby = user();
END$$
DELIMITER ;
Trigger che registra le modifiche
UPDATE employees
SET lastName = 'Phan'
WHERE employeeNumber = 1056
Trigger per il controllo dei dati
Se qualcosa non va si segnala un errore
La sintassi è la stessa vista nelle SP
SIGNAL sqlstate '45001' SET message_text = "No way !";
Trigger per il controllo dei dati
Creare una UDF che riceve in input un numero e ne restituisca il doppio, ed usarla in una query
Hint: IF NEW.creditLimit >
OLD.creditLimit
CREATE TRIGGER trg_beforeUpdateCustomer
BEFORE UPDATE ON customers
FOR EACH ROW BEGIN
IF NEW.creditLimit > OLD.creditLimit THEN
SIGNAL sqlstate '45001' SET message_text = "Basta crediti!";
END IF;
END
Conflitti tra trigger
Se vi sono più trigger associati allo stesso evento, SQL:1999 prescrive
- vengono eseguiti i trigger BEFORE statement-level
- vengono eseguiti i trigger BEFORE row-level
- si applica la modifica e si verificano i vincoli di integrità definiti sulla base di dati
- vengono eseguiti i trigger AFTER row-level
- vengono eseguiti i trigger AFTER statement-level
Conflitti tra trigger
Se vi sono più trigger della stessa categoria, l’ordine di esecuzione viene scelto dal sistema in un modo che dipende dall’implementazione
Modello di esecuzione
- SQL:1999 prevede che i trigger vengano gestiti in un Trigger Execution Context (TEC)
- l’esecuzione dell’azione di un trigger può produrre eventi che fanno scattare altri trigger, che dovranno essere valutati in un nuovo TEC interno
- in ogni istante possono esserci più TEC per una transazione, uno dentro l’altro, ma uno solo può essere attivo
Modello di esecuzione
- per i trigger row-level il TEC tiene conto di quali tuple sono già state considerate e quali sono da considerare
- si ha quindi una struttura a stack
- TEC0 -> TEC1 -> … -> TECn
- quando un trigger ha considerato tutti gli eventi, il TEC si chiude e si passa al trigger successivo
Interazione tra trigger
| Dipartimento | |
|---|---|
| NroDip | MatricolaMGR |
| 1 | 50 |
| Progetto | |
|---|---|
| NroProg | Obiettivo |
| 10 | NO |
| 20 | NO |
| Impiegato | ||||
|---|---|---|---|---|
| Matricola | Nome | Salario | NDip | NProg |
| 50 | Rossi | 59.000 | 1 | 20 |
| 51 | Verdi | 56.000 | 1 | 10 |
| 52 | Bianchi | 50.000 | 1 | 20 |
Trigger T1: Bonus
Evento: update di Obiettivo in Progetto
Condizione: Obiettivo = ‘SI’
Azione: incrementa del 10% il salario degli impiegati coinvolti
Trigger T1: Bonus
CREATE TRIGGER Bonus
AFTER UPDATE OF Obiettivo ON Progetto
FOR EACH ROW
WHEN NEW.Obiettivo = 'SI'
BEGIN
update Impiegato
set Salario = Salario*1.10
where NProg = NEW.NroProg;
END;
Trigger T2: ControllaIncremento
Evento: update di Salario in Impiegato
Condizione: nuovo salario maggiore di quello del manager
Azione: decrementa il salario rendendolo uguale a quello del manager
Trigger T2: ControllaIncremento
CREATE TRIGGER ControllaIncremento
AFTER UPDATE OF Salario ON Impiegato
FOR EACH ROW
DECLARE X number;
BEGIN
SELECT Salario into X FROM Impiegato JOIN Dipartimento
ON Impiegato.Matricola = Dipartimento.MatricolaMGR
WHERE Dipartimento.NroDip= NEW.NDip;
IF NEW.Salario > X
update Impiegato set Salario = X
where Matricola = NEW.Matricola;
ENDIF;
END;
Trigger T3: ControllaDecremento
Evento: update di Salario in Impiegato
Condizione: decremento maggiore del 3%
Azione: decrementa il salario del solo 3%
Trigger T3: ControllaDecremento
CREATE TRIGGER ControllaDecremento
AFTER UPDATE OF Salario ON Impiegato
FOR EACH ROW
WHEN (NEW.Salario < OLD.Salario * 0.97)
BEGIN
update Impiegato
set Salario=OLD.Salario*0.97
where Matricola = NEW.Matricola;
END;
Attivazione di T1
UPDATE Progetto SET Obiettivo = 'SI' WHERE NroProg = 10Evento: update dell'attributo Obiettivo in Progresso
Condizione: vera
Azione: si incrementa del 10% il salario di Verdi
| Progetto | |
|---|---|
| NroProg | Obiettivo |
| 10 | SI |
| 20 | NO |
| Impiegato | ||||
|---|---|---|---|---|
| Matricola | Nome | Salario | NDip | NProg |
| 50 | Rossi | 59.000 | 1 | 20 |
| 51 | Verdi | 61.600 | 1 | 10 |
| 52 | Bianchi | 50.000 | 1 | 20 |
Attivazione di T2
Evento: update di Salario in Impiegato
Condizione: vera (il salario dell'impiegato Verdi supera quello del manager Rossi)
Azione: si modifica il salario di Verdi rendendolo uguale a quello del manager Rossi
| Impiegato | ||||
|---|---|---|---|---|
| Matricola | Nome | Salario | NDip | NProg |
| 50 | Rossi | 59.000 | 1 | 20 |
| 51 | Verdi | 59.000 | 1 | 10 |
| 52 | Bianchi | 50.000 | 1 | 20 |
Attivazione di T3
Evento: update dell'attributo salario in Impiegato
Condizione: vera (il salario di Verdi è stato decrementato per più del 3%)
Azione: si decrementa il salario di Verdi del solo 3%
| Impiegato | ||||
|---|---|---|---|---|
| Matricola | Nome | Salario | NDip | NProg |
| 50 | Rossi | 59.000 | 1 | 20 |
| 51 | Verdi | 59.752 | 1 | 10 |
| 52 | Bianchi | 50.000 | 1 | 20 |
- Si attiva nuovamente T3 - condizione è falsa
- Si attiva T2 - condizione vera
Attivazione di T2
| Impiegato | ||||
|---|---|---|---|---|
| Matricola | Nome | Salario | NDip | NProg |
| 50 | Rossi | 59.000 | 1 | 20 |
| 51 | Verdi | 59.000 | 1 | 10 |
| 52 | Bianchi | 50.000 | 1 | 20 |
- Si attiva nuovamente T3 - condizione è falsa
- L'attivazione dei trigger ha raggiunto lo stato di terminazione
Tecniche di accesso ai dati
Accedere ai dati
Data Consumer
Tool e linguaggi che lavorano con i dati
Data Providers
Sorgente dei dati
Breve storia dell’accesso ai dati
- API proprietarie (es: VB Objects)
- Data Access Objects (DAO/Jet)
- Open Database Connectivity (ODBC)
- OLE for Databases (OLE/DB)
- ActiveX Data Objects (ADO)
- .NET→ ADO.NET
- Object-relational Mapping (ORM)
Sistemi proprietari
- dipendono da Data Consumer
- linguaggio e piattaforma
- dipendono da Data Provider
- …a volte ancora necessari
- es: accedere ad un MDB in linux
ODBC
- sviluppato da Microsoft e ceduto al W3C
- pensato per motori relazionali
- indipendente da DBMS e sistema operativo
ODBC
Componenti principali
- ODBC Driver: layer tra l’applicazione ed il DBMS
- l’applicazione usa un Driver Manager per accedere ai vari driver
- Data Source Names (DNS): informazioni per la connessione; gestiti dal Driver Manager
ODBC
PRO:
- non intrusivo sul server; sono i Driver ad avere un’interfaccia verso i Data Provider
Contro:
- non sempre esiste il driver (gratis)…
- API difficili da usare
- richiedono molto codice da implementare nell’applicazione
ActiveX Data Objects (ADO)
- interfaccia più user-friendly per il programmatore
- parte di Microsoft Data Access Components (MDAC)
- qualsiasi fonte ODBC o OLE/DB
- accessibile da diversi linguaggi (C++, Java, .NET, …)
ADO Connection String
Ci sono tanti possibili provider
- serve la password?
- devo dare un nome di file?
- l’indirizzo di un server?
ADO Connection String
Stringa di connessione:
- serie di coppie chiave-valore
- separatore: “;”
- chiave=valore
ADO Connection String
ODBC
DSN=PropDB;Uid=admin;Pwd=;
Access
Provider=‘Microsoft.JET.OLEDB.4.0’;Data Source=‘C:\test.mdb’
ADO Connection String
SQL Server
Server=myServerAddress;Database=myDB;UserId=myUsername;Password=myPassword;
MySql
Server=myServerAddress;Database=myDB;Uid=myUsername;Pwd=myPassword;
ADO .NET
Evoluzione di ADO
ADO .NET è una collezione di classi, interfacce, strutture e tipi che gestiscono l’accesso ai dati da fonti relazionali all’ interno del .NET Framework
ADO vs ADO .NET
ADO
- progettato per accessi connessi
- totalmente legato al modello fisico dei dati
RecordSetè il contenitore dei datiRecordSetè una tabella che contiene tutti i dati- se si vuole estrarre dati da più di una tabella: JOIN
- i dati sono “flattened”: si perdono le relazioni, la navigazione è sequenziale
ADO vs ADO .NET
ADO .NET
- progettato per accessi disconnessi
- può modellare i dati a livello logico
- il DataSet rimpiazza il RecordSet
- DataSet contiene tabelle multiple
- estrarre dati da più di una tabella non richiede una JOIN
- Relationships conservate e la navigazione è relazionale
Classi principali di ADO .NET
Connection
- usato per parlare al DB
- le proprietà includono dataSource, username e password
Command
- Uno statement SQL o Stored Procedure
Classi principali di ADO .NET
DataReader
- sola lettura monodirezionale, ma molto veloce
- connesso
- una vista unidirezionale connessa dei dati (simile ad ADO Recordset)
DataAdapter
- lettura e scrittura
- disconnesso
- gestisce DataSet
JDBC
Equivalente JAVA di ADO .NET
Esistono 4 tipologie diverse di JDBC
Tipo 1: JDBC-ODBC bridge
- il driver dipende dal SO (chiamate ad ODBC)
- PRO: se ho il driver ODBC posso accedere al DB
- CONTRO: overhead, ed il driver ODBC deve essere installato sul client
- fornito in Java: sun.jdbc.odbc.JdbcOdbcDriver
Tipo 2: Native-API Driver
- comunica con le API del DB (dipende dal SO)
- PRO: più veloce del Tipo 1
- CONTRO: le librerie client del DB vanno installate sulle macchine
Tipo 3: Network-Protocol Driver
- MiddleWare Driver
- comunica con un application server (es: J2EE) che converte le chiamate nel linguaggio del DB
Tipo 4: Database-Protocol Driver
- Pure Java Driver
- PRO: Platform-independent
- CONTRO: ogni DBMS deve scrivere il suo
ADO .NET -> JDBC
SqlConnection -> Connection
SqlCommand -> Statement
SqlDataReader -> ResultSet
Caricare il driver
// The newInstance() call is a work around for some
// broken Java implementations
Class.forName("com.mysql.cj.jdbc.Driver").newInstance();
Connettersi al DB
con = DriverManager.getConnection("jdbc:mysql://localhost/" +
"DBNAME?" +
"user=XXX&" +
"password=YYY");
Eseguire una query
Statement stmt = null;
ResultSet rs = null;
try {
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT foo FROM bar");
}
catch (SQLException ex){
// handle any errors
}
finally {
// some controls...
rs.close();
stmt.close();
}
Leggere i risultati
ResultSet rs = stm.executeQuery("select * from persone");
while (rs.next()) {
String col1 = rs.getString("colonna1");
}
Modificare i dati
stm.executeUpdate("UPDATE tabella SET colonna = val ...");
stm.executeUpdate("INSERT ...");
stm.executeUpdate("DELETE ...");
Prepared Statement
String sql = "SELECT nome FROM persone WHERE cognome = ?";
PreparedStatement prepared = connection.prepareStatement(sql);
prepared.setString(1, "Rossi");
ResultSet rs = stm.executeQuery();
Prepared Statement
String sql = "insert into persone (cognome, nome, eta) values (?,?,?)";
PreparedStatement prepared = connection.prepareStatement(sql);
prepared.setString(1, "Marroni");
prepared.setString(2, "Enrico");
prepared.setInt(3, 55);
prepared.executeUpdate();
Chiamare una SP
CallableStatement cStm = con.prepareCall("{call sp_name(?, ?)}");
cStm.setString(1, "abcdefg");
boolean hadResults = cStm.execute();
Parametri SP
CallableStatement cStm = con.prepareCall("{call sp_name(?, ?)}");
cStm.registerOutParameter(2, Types.INTEGER);
// or cStmt.registerOutParameter("inOutParam", Types.INTEGER);
cStm.setString(1, "abcdefg");
cStm.setString(2, 1);
// or cStmt.setString("inputParam", 1);
boolean hadResults = cStm.execute();
Risultato SP
boolean hadResults = cStm.execute();
while (hadResults) {
ResultSet rs = cStm.getResultSet();
hadResults = cStm.getMoreResults();
}
int outputValue = cStm.getInt(2); // index-based
… cose da non fare
Scanner in = new Scanner(System.in);
String s = in.nextLine();
String sql = "SELECT * FROM Users WHERE UserId = "+s+";"
ResultSet rs = stm.executeQuery(sql);
while (rs.next()) {
String col1 = rs.getString("...");
}
SQL Injections
Input: 100 OR 1=1
String sql = "SELECT * FROM Users WHERE UserId = "+s+";"
una volta inseriti i valori diventa:
SELECT * FROM Users WHERE UserId = 100 OR 1=1;
SQL Injections
Input: 100 OR 1=1
String sql = "SELECT UserId, Name, Password FROM Users WHERE UserId = "+s+";"
una volta inseriti i valori diventa:
SELECT UserId, Name, Password FROM Users WHERE UserId = 100 OR 1=1;
SQL Injections
Input: 100; DROP TABLE customers
String sql = "SELECT * FROM Users WHERE UserId = "+s+";"
una volta inseriti i valori diventa:
SELECT * FROM Users WHERE UserId = 100; DROP TABLE customers;
SQL Injections
Scanner in = new Scanner(System.in);
String user = in.nextLine();
String password = in.nextLine();
String sql = "SELECT * FROM Users WHERE Name ='" + user + "' AND Pass ='" + password + "';"
ResultSet rs = stm.executeQuery(sql);
if (rs.next()) {
// autenticato
}
SQL Injections
Input utente: ' or ''='
Input password: ' or ''='
String sql = "SELECT * FROM Users WHERE Name ='" + user + "' AND Pass ='" + password + "'"
una volta inseriti i valori diventa:
SELECT * FROM Users WHERE Name ='' or ''='' AND Pass ='' or ''='';
SQL Injections
Scanner in = new Scanner(System.in);
String categoria = in.nextLine();
String sql = "SELECT name, description " +
"FROM products "+
"WHERE category ='" + categoria + "' and release = 1;"
ResultSet rs = stm.executeQuery(sql);
while (rs.next()) {
// autenticato
}
SQL Injections
Input categoria: ' UNION SELECT user, password FROM users--
String sql = "SELECT name, description " +
"FROM products "+
"WHERE category ='" + categoria + "' and release = 1;"
una volta inseriti i valori diventa:
SELECT name, description FROM products
WHERE category ='' UNION SELECT user, password FROM users--' and release = 1;
SQL Injections

Stringa inserita: ";UPDATE ... --
Breve storia dell’accesso ai dati
- API proprietarie (es: VB Objects)
- Data Access Objects (DAO/Jet)
- Open Database Connectivity (ODBC)
- OLE for Databases (OLE/DB)
- ActiveX Data Objects (ADO)
- .NET→ ADO.NET
- Object-relational Mapping (ORM)
Object-relational Mapping
Integrazione tra linguaggi di programmazione ad oggetti e DBMS relazionali
String sql = "SELECT ... FROM persons WHERE id = 10";
Statement = con.createStatement();
ResultSet res = cmd.executeQuery(sql);
String name = res[0]["FIRST_NAME"];
diventa
Person p = repository.GetPerson(10);
String name = p.FirstName;
SQL? Inutile?
- impossibile usare ORM se non si sa progettare DB
- molti sistemi non li usano
- a volte meno efficiente che non scrivere query a mano
Object-relational Mapping
Cosa si fa?
- conversione di oggetti in valori scalari
- mantenimento delle relazioni tra gli oggetti
Tanti framework diversi risolvono il problema
Object-relational Mapping
Java Persistance API (JPA)
- Hibernate
- EclipseLink
- TopLink
Object-relational Mapping
Framework .NET
- LINQ to SQL (solo SQL server)
- ADO Entity Framework
- NHibernate
Hibernate
- utilizzabile in JAVA (estende JPA)
- utilizzabile in C# (NHibernate)
- supporta moltissimi DBMS diversi
Configurare [N]Hibernate
Occorre specificare
- lato Java: quale implementazione JPA usare
- Connection Proveider
- dettagli della connessione
- strategia generazione delle tabelle
- lista delle entità
Configurazione a run-time
File di configurazione
Mapping
public class Studente{
private long idStud;
}
… come gli dico che id è la chiave primaria?
Mapping
Impostazione chiave primaria
- file XML che definisce le impostazioni
annotazioni (attributi in C#)
@Id @GeneratedValue(strategy = GenerationType.AUTO) private long idStud;
Mapping
Come faccio mapping?
@Entity
@Table(name = "Studente")
public class Studente{
@Id
@Column(name = "idStud")
private long idStud;
@Column(name = "nome")
String nome;
}
EntityManager, Factory & co
EntityManagerFactory
- apre il database
- aggiorna la struttura del database
- operazione pesante e complicata
- ne basta una per applicazione (static)
EntityManager, Factory & co
EntityManager
- connessione di breve durata al DB
- permette di eseguire operazioni sul DB
EntityManager, Factory & co
EntityTransaction
- racchiude operazioni che modificano il contenuto del DB
Query
- utilizzano una sintassi particolare (JPQL)
Entity Object Life Cycle
Persist o Merge?
persist()
- si applica su nuove entità
- genera una INSERT in SQL
- non restituisce nulla
Persist o Merge?
merge()
- entità nuova o detached
- genera una INSERT o una UPDATE
- restituisce la versione managed dell’oggetto
tutto va sempre racchiuso in una transazione
Ottenere oggetti
Ricerca per chiave primaria
Employee employee = em.find(Employee.class, 1);
JPA Query Language
Query q1 = em.createQuery
Ottenere oggetti
JPA Criteria Query
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Country> q = cb.createQuery(Country.
class);
Root<Country> c = q.from(Country.class);
q.select(c);
Named Query
@NamedQuery(name="Country.findAll", query="SELECT c FROM
Country c")
Accesso Lazy
Un oggetto è lazy se non contiene tutti i dati ma sa come ottenerli
Effettua la query solo quando servono i dati:
- ottengo studente XYZ, non vado a leggere subito i dati di tutti gli esami e di tutti i corsi collegati
opzione dell’annotazione della relationship
@OneToMany(fetch=javax.persistence.FetchType.LAZY)
Triggers
Equivalente dei triggers nel mondo JPA
creo un metodo privato ma senza parametri
@PreUpdate@PrePersist- …
Stored Procedure
Non posso crearle con JPA
Posso richiamarle (JPA >= 2.1)
@NamedStoredProcedureQuery(
name = "ReadAddressById",
resultClasses = Address.class,
procedureName = "READ_ADDRESS",
parameters = {
@StoredProcedureParameter(mode=IN,
name="P_ADDRESS_ID", type=Long.class)
}
)
@Entity
public class Address {
...
}
Versioni
Hibernate può tenere traccia delle modifiche operate sugli oggetti
@org.hibernate.envers.Audited
Versioni
Posso ricercare versioni precedenti dello stesso oggetto:
AuditReader reader = AuditReaderFactory.get(em)
Event firstRevision = reader.find(Event.class, 2L, 1);
Event secondRevision = reader.find(Event.class, 2L, 2);
Progettazione base di dati
Ricordate?
In ogni base di dati esistono:
- lo schema: descrive la struttura della base di dati e non varia nel tempo
- nel modello relazionale: intestazioni delle tabelle
- l’istanza: i valori attuali, che possono variare anche rapidamente
- nel modello relazionale: le righe delle tabelle
Circle of life
- Studio di fattibilità: definizione costi e priorità
- Raccolta e analisi dei requisiti: studio delle proprietà del sistema
- Progettazione: di dati e funzioni
- Realizzazione (prototipo?)
- Validazione e collaudo: sperimentazione
- Funzionamento: il sistema diventa operativo
Modelli principali
- modelli logici
- modelli concettuali
Modelli logici
utilizzati nei DBMS esistenti per l’organizzazione dei dati
- utilizzati dai programmi
- indipendenti dalle strutture fisiche
- esempi: relazionale, reticolare, gerarchico…
Modelli concettuali
rappresentano i dati in modo indipendente da ogni sistema
- cercano di descrivere i concetti del mondo reale
- sono utilizzati nelle fasi preliminari di progettazione
- il più noto è il modello Entity-Relationship
Modelli concettuali, perché?
Proviamo a modellare una applicazione definendo direttamente lo schema logico della base di dati
Da dove cominciamo?
dobbiamo pensare subito a come correlare le varie tabelle (chiavi etc.)
Modelli concettuali, perché?
Modelli concettuali
- permettono di rappresentare le classi di dati di interesse e le loro correlazioni
- prevedono efficaci rappresentazioni grafiche (utili anche per documentazione)
- indipendenti dal DBMS scelto
Modello Entity-Relationsip
Entità - Relazione
Il più diffuso modello concettuale, ne esistono molte versioni (più o meno) diverse
Aspeti chiavi modello E-R
- entità
- relationship
- attributo
- identificatore
- generalizzazione
Entità
Classe di oggetti (fatti, persone, cose) della applicazione di interesse con proprietà comuni e con esistenza autonoma
Esempi:
impiegato, città, conto corrente, ordine, fattura
Istanza: elemento della classe
nello schema concettuale rappresentiamo le entità, non le singole istanze
Rappresentazione di entità
- nomi espressivi
- opportune convenzioni: singolare
Relationship
Legame logico fra due o più entità, rilevante nell’applicazione di interesse
Esempi:
- Residenza (fra persona e città)
- Esame (fra studente e corso)
Chiamata anche: relazione, correlazione, associazione
Rappresentazione di relazione
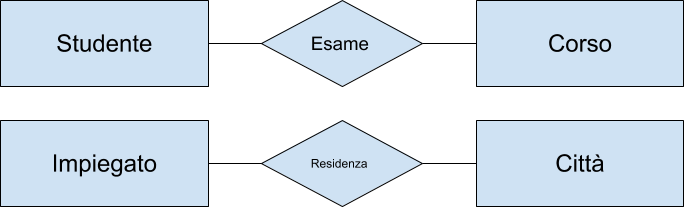
- nomi espressivi
- opportune convenzioni: singolare e sostantivi invece che verbi (se possibile)
Esempi di istanze
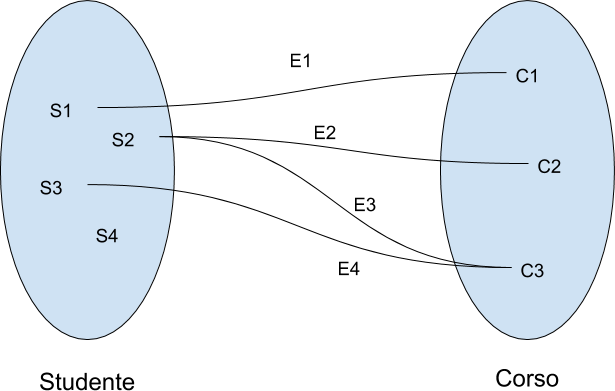
Due relazioni sulla stessa entità
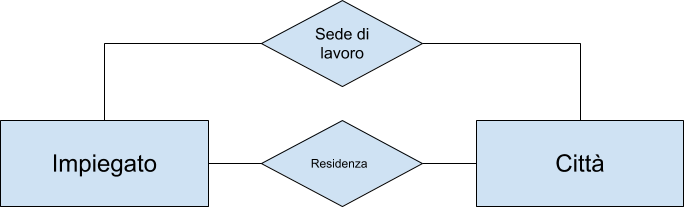
Relationship n-aria
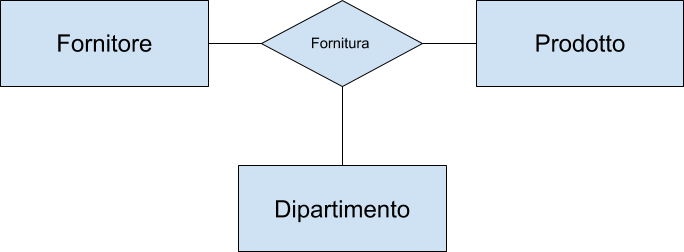
Relationship ricorsiva
Coinvolge due volte la stessa entità
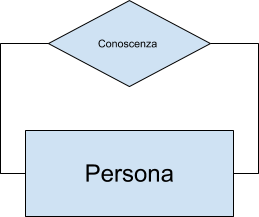
Relationship ricorsiva con ruoli
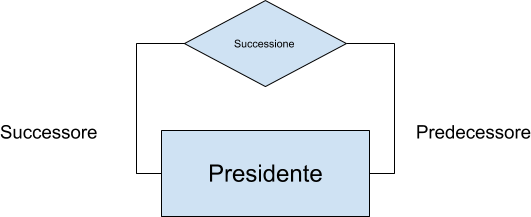
Relationship ternaria ricorsiva
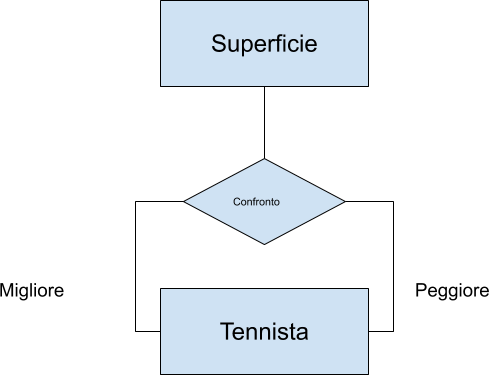
Attributo
- proprietà elementare di un’entità o di una relationship, di interesse per l’applicazione
- associa ad ogni occorrenza di entità o relationshio un valore del dominio dell’attributo
Rappresentazione di attributi
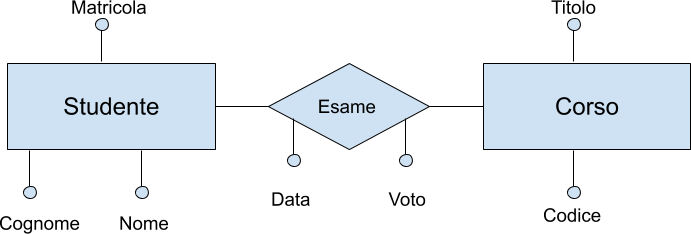
Esempi di istanze
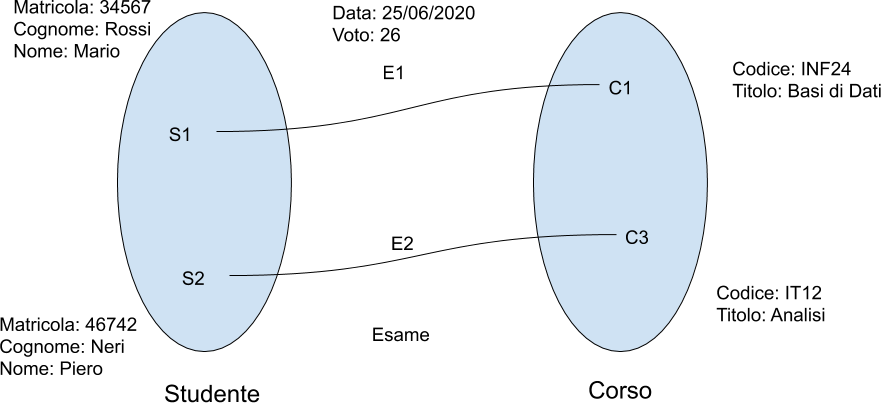
Attributi composti
- raggruppano attributi di una medesima entità o relationship che presentano affinità nel loro significato o uso
- es: Via, Numero civico e CAP formano “Indirizzo”
Rappresentazione grafica
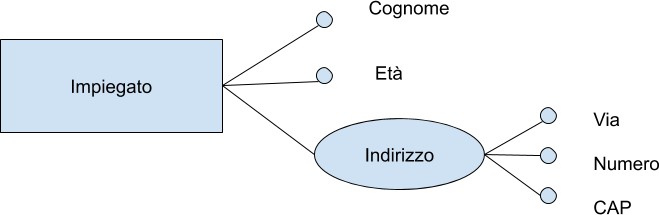
Rappresentazione grafica
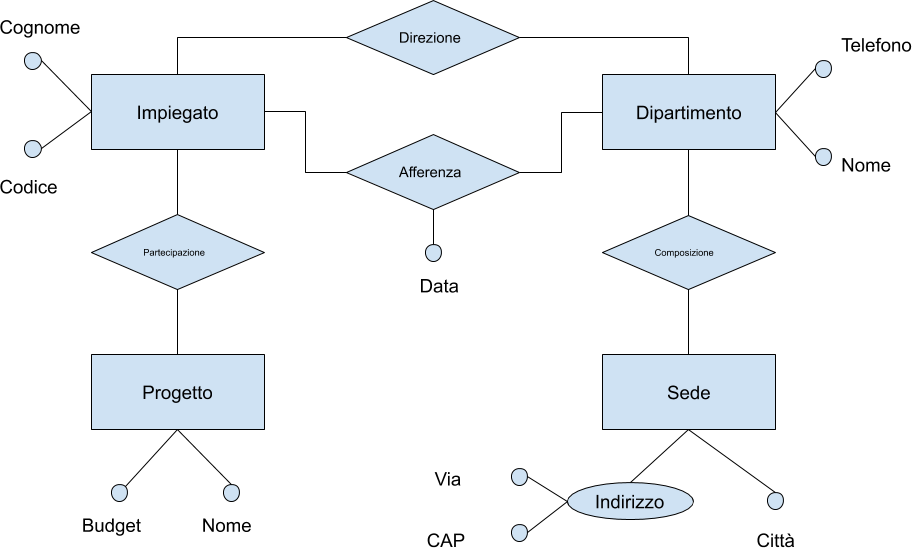
Altri costrutti del modello E-R
- cardinalità
- identificatore
- generalizzazione
Altri costrutti del modello E-R
Cardinalità
- di relationship
- di attributo
Identificatore
- interno
- esterno
Cardinalità
Coppia di valori associati ad ogni entità che partecipa ad una relationship
Specificano il numero min e max di occorrenze di una relationship a cui una occorrenza di una entità può partecipare
Esempio di cardinalità

Per semplicità useremo tre simboli:
- 0 e 1 per la cardinalità minima
- 0 = "partecipazione opzionale"
- 1 = "partecipazione obbligatoria"
- 1 e N per la cardinalità massima
- N = nessun limite
Istanze di Residenza
Cardinalità di Residenza

Tre tipi di Relationships
Con riferimento alle cardinalità massime, abbiamo realtionship:
- uno a uno
- uno a molti
- molti a molti
Relationship molti a molti
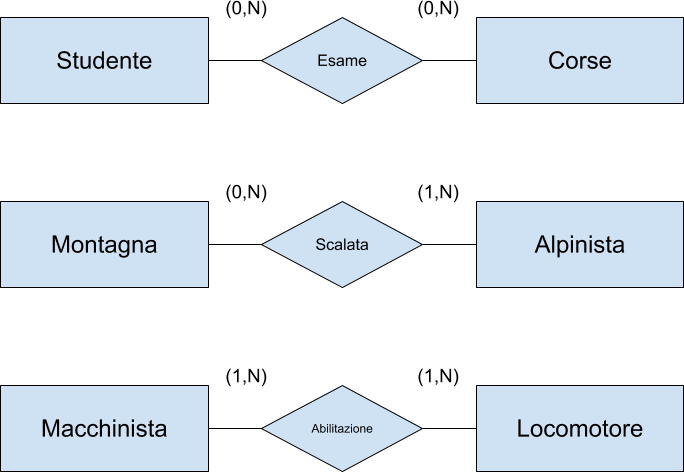
Relationship uno a molti
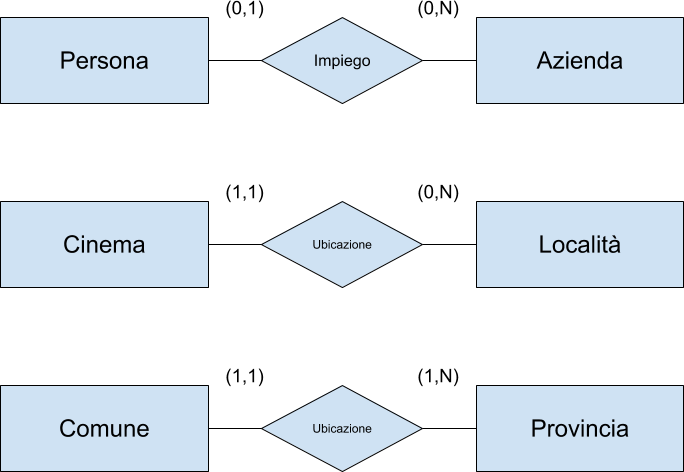
Cardinalità di attributi
È possibile associare delle cardinalità anche agli attributi, con due scopi:
- indicare opzionalità ("informazione incompleta")
- indicare attributi multivalore
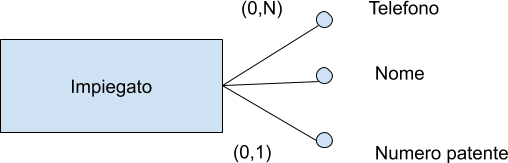
Identificatore di una entità
Strumento per l’identificazione univoca delle occorrenze di un’entità costituito da:
- attributi dell’entità → identificatore interno
- (attributi +) entità esterne attraverso relationship → identificatore esterno
Identificatore di una entità
Attenzione:
- ogni entità deve possedere almeno un identificatore, ma può averne in generale più di uno
- una identificazione esterna è possibile solo attraverso una relationship a cui l’entità da identificare partecipa con cardinalità (1,1)
Identificatori interni
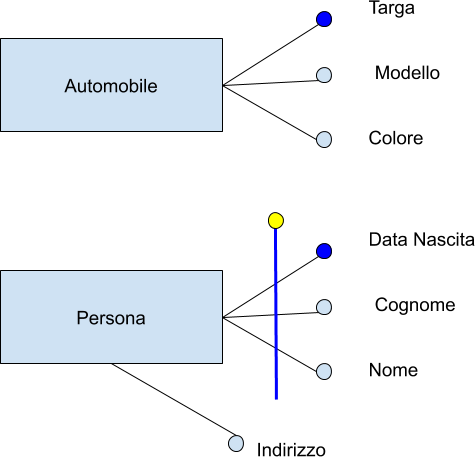
Identificatori esterni
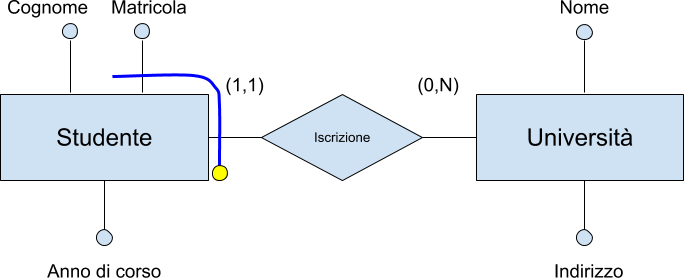
Generalizzazione
Mette in relazione una o più entità $E_1, E_2, \dots, E_n$ con una entità $E$
- $E$ è generalizzazione di $E_1, E_2, \dots, E_n$
- $E_1, E_2, \dots, E_n$ sono specializzazioni (o sottotipi) di $E$
Generalizzazione
Ereditarietà
Tutte le proprietà (attributi, relationship, altre generalizzazioni) dell’entità genitore vengono ereditate dalle entità figlie e non rappresentate esplicitamente
Rappresentazione grafica
Tipi di generalizzazioni
- totale se ogni occorrenza dell’entità genitore è occorrenza di almeno una delle entità figlie, altrimenti è parziale
- esclusiva se ogni occorrenza dell’entità genitore è occorrenza di al più una delle entità figlie, altrimenti è sovrapposta
Tipi di generalizzazioni
Consideriamo (senza perdita di generalità) solo generalizzazioni esclusive e distinguiamo fra totali e parziali
Generalizzazione totale
Generalizzazione parziale
Documenti aggiuntivi
Dizionario dei dati
- entità
- relationship
Vincoli non esprimibili
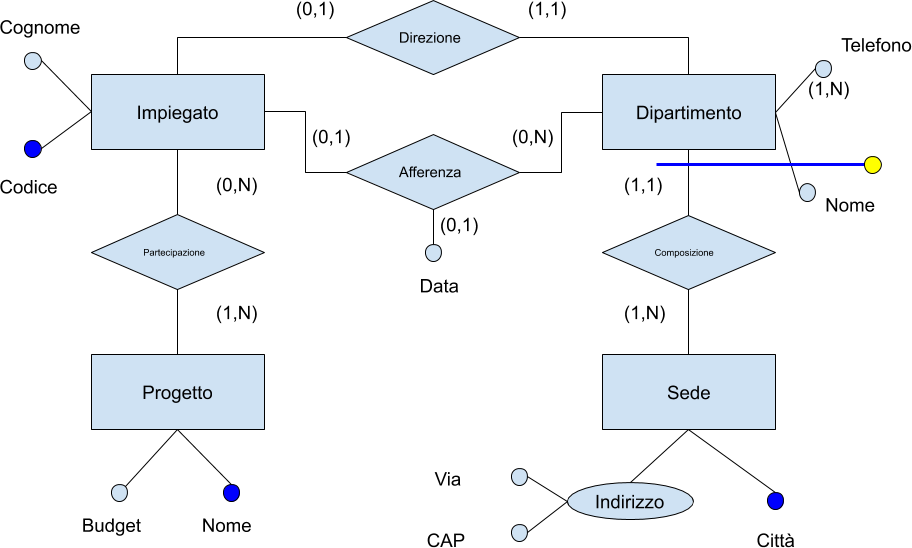
Dizionario dei dati (entità)
| Entità | Descrizione | Attributi | Identificatore |
|---|---|---|---|
| Impiegato | Dipendente dell’azienda | Codice, Cognome, Stipendio | Codice |
| Progetto | Progetti aziendali | Nome, Budget | Nome |
| Dipartimento | Struttura aziendale | Nome, Telefono | Città |
| Sede | Sede dell’azienda | Città, Indirizzo | Città |
Dizionario dei dati (relationship)
| Relazioni | Descrizione | Componenti | Attributi |
|---|---|---|---|
| Direzione | Direzione di dipartimento | Impiegato, Dipartimento, Stipendio | |
| Afferenza | Afferenza a dipartimento | Impiegato, Dipartimento | Data |
| Partecipazione | Partecipazione a un progetto | Impiegato, Progetto | |
| Composizione | Composizione dell’azienda | Dipartimento, Sede |
Vincoli non esprimibili
| Vincoli di integrità sui dati |
|---|
| (1) Il direttore di un dipartimento deve afferire a tale dipartimento |
| (2) Un impiegato non deve avere uno stipendio maggiore del direttore del suo dipartimento |
| (3) Un dipartimento con sede a Roma deve essere diretto da un impiegato con anzianità > 10 |
| (4) Un impiegato che non afferisce a nessun dipartimento non deve partecipare a nessun progetto |
Esercizio: anagrafica
Le persone hanno CF, cognome ed età; gli uomini anche la posizione militare; gli impiegati hanno lo stipendio e possono essere segretari, direttori o progettisti (un progettista può essere anche responsabile di progetto); gli studenti (che non possono essere impiegati) un numero di matricola; esistono persone che non sono né impiegati né studenti (ma i dettagli non ci interessano)
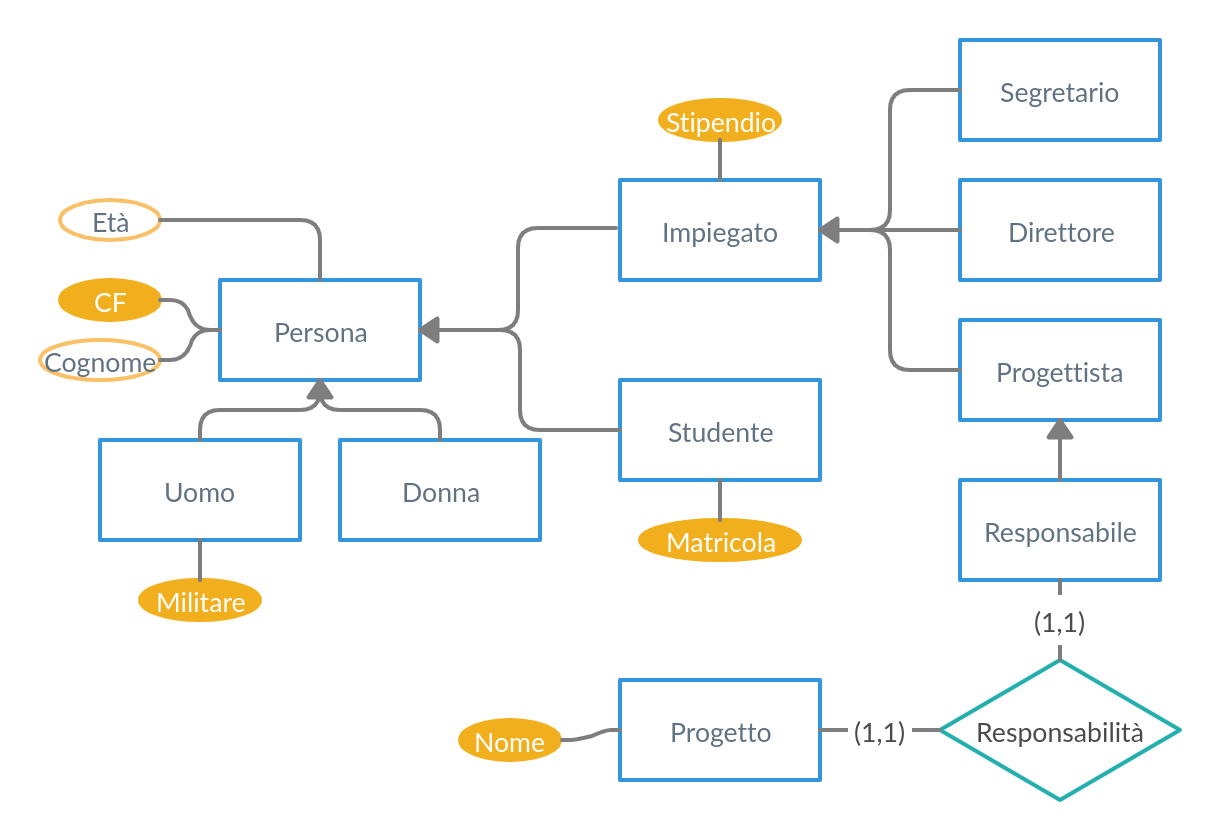
Esercizio: biblioteca
- oggetto dei prestiti sono esemplari (detti anche copie) di singoli volumi, identificati attraverso un numero di inventario;
- ogni volume è relativo ad una specifica edizione (che può essere articolata in più volumi, anche in modo diverso dalle altre edizioni) di un'opera
- un volume può essere presente in più copie
- una edizione è caratterizzata dall'opera, dalla collana e dall'anno
- riassumendo ed esemplificando, è possibile prendere in prestito la seconda copia del terzo volume de "I Miserabili", edizione Mondadori, collana Oscar, del 1975
- ogni collana ha un nome e un codice e un editore
- ogni editore ha un nome e un codice
- ogni opera ha un titolo, un autore e un anno di prima pubblicazione
- per ogni prestito in corso (quelli conclusi non interessano), sono rilevanti la data prevista di restituzione e l'utente (che può avere più volumi in prestito contemporaneamente), con codice identificativo, nome, cognome e recapito telefonico
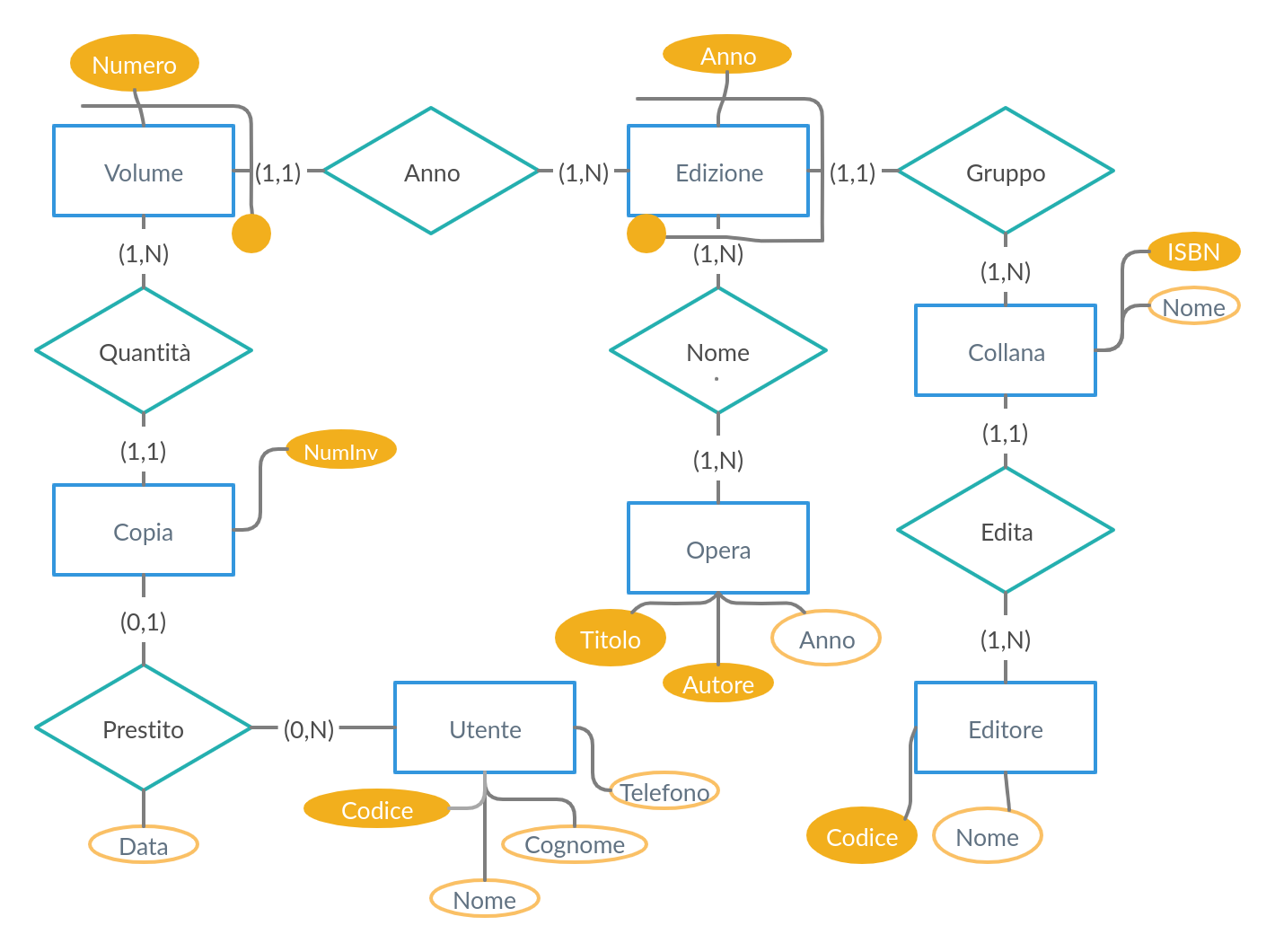
Strategie di progetto
top-down
bottom-up
Top-down
- definisco il problema in linea generale
- rifinisco le varie parti sempre di più
- contro: devo finire tutta la progettazione prima di poter iniziare
- pro: completa comprensione del sistema
Bottom-up
- parti individuali sono specificate in dettaglio
- connessione tra le varie parti
- contro: posso fare degli errori nella progettazione dei singoli moduli
- pro: posso iniziare subito a sviluppare (e testare)
Analisi dei requisiti
Diverse attività (interconnesse)
- acquisizione dei requisiti
- analisi dei requisiti
- costruzione dello schema concettuale
- costruzione del glossario
Analisi dei requisiti
Possibili fonti
- utenti, attraverso interviste
- documentazione esistente: normative, regolamenti interni, procedure aziendali e realizzazioni preesistenti
- modulistica
Acquisizione per interviste
Il reperimento dei requisiti è un’attività difficile e non standardizzabile
- utenti diversi possono fornire informazioni diverse
- verificare la coerenza, chiedere esempi
- utenti a livello più alto hanno spesso una visione più ampia ma meno dettagliata
- le interviste portano spesso ad un’acquisizione dei requisiti per raffinamenti successivi
Scrivere i requisiti
Regole generali
- standardizzare la struttura delle frasi
- suddividere le frasi articolate
- separare le frasi sui dati da quelle sulle funzioni
- costruire un glossario dei termini
- individuare omonimi e sinonimi e unificare i termini
Esempio: società di formazione
| Società di formazione (1) |
|---|
| Si vuole realizzare una base di dati per una società che eroga corsi, di cui vogliamo rappresentare i dati dei partecipanti ai corsi e dei docenti. Per gli studenti (circa 5000), identificati da un codice, si vuole memorizzare il codice fiscale, il cognome, l'età, il sesso, il luogo di nascita, il nome dei loro attuali datori di lavoro, i posti dove hanno lavorato in precedenza insieme al periodo, l'indirizzo e il numero di telefono, i corsi che hanno frequentato (i corsi sono in tutto circa 200) e il giudizio finale. |
Esempio: società di formazione
| Società di formazione (2) |
|---|
| Rappresentiamo anche i seminari che stanno attualmente frequentando e, per ogni giorno, i luoghi e le ore dove sono tenute le lezioni. I corsi hanno un codice, un titolo e possono avere varie edizioni con date di inizio e fine e numero di partecipanti. Se gli studenti sono liberi professionisti, vogliamo conoscere l'area di interesse e, se lo possiedono, il titolo. Per quelli che lavorano alle dipendenze di altri, vogliamo conoscere invece il loro livello e la posizione ricoperta. |
Esempio: società di formazione
| Società di formazione (3) |
|---|
| Per gli insegnanti (circa 300), rappresentiamo il cognome, l'età, il posto dove sono nati, il nome del corso che insegnano, quelli che hanno insegnato nel passato e quelli che possono insegnare. Rappresentiamo anche tutti i loro recapiti telefonici. I docenti possono essere dipendenti interni della società o collaboratori esterni. |
Glossario dei termini
| Termine | Descrizione | Sinonimi | Collegamenti |
|---|---|---|---|
| Partecipante | Persona che partecipa ai corsi | Studente | Corso, Società |
| Docente | Docente dei corsi. Può essere esterno | Insegnante | Corso |
| Corso | Corso organizzato dalla società. Può avere più edizioni | Seminario | Docente |
| Società | Ente presso cui i partecipanti lavorano o hanno lavorato | Posti | Partecipante |
Gruppi di frasi omogenee
| Frasi di carattere generale |
|---|
| Si vuole realizzare una base di dati per una società che eroga corsi, di cui vogliamo rappresentare i dati dei partecipanti ai corsi e dei docenti. |
Gruppi di frasi omogenee
| Frasi relative ai partecipanti |
|---|
| Per i partecipanti (circa 5000), identificati da un codice, rappresentiamo il codice fiscale, il cognome, l'età, il sesso, la città di nascita, i nomi dei loro attuali datori di lavoro e di quelli precedenti (insieme alle date di inizio e fine rapporto), le edizioni dei corsi che stanno attualmente frequentando e quelli che hanno frequentato nel passato, con la relativa votazione finale in decimi. |
Gruppi di frasi omogenee
| Frasi relative ai datori di lavoro |
|---|
| Relativamente ai datori di lavoro presenti e passati dei partecipanti, rappresentiamo il nome, l'indirizzo e il numero di telefono. |
Gruppi di frasi omogenee
| Frasi relative ai corsi |
|---|
| Per i corsi (circa 200), rappresentiamo il titolo e il codice, le varie edizioni con date di inizio e fine e, per ogni edizione, rappresentiamo il numero di partecipanti e il giorno della settimana, le aule e le ore dove sono tenute le lezioni. |
Gruppi di frasi omogenee
| Frasi relative a tipi specifici di partecipanti |
|---|
| Per i partecipanti che sono liberi professionisti, rappresentiamo l'area di interesse e, se lo possiedono, il titolo professionale. Per i partecipanti che sono dipendenti, rappresentiamo invece il loro livello e la posizione ricoperta. |
Gruppi di frasi omogenee
| Frasi relative ai docenti |
|---|
| Per i docenti (circa 300), rappresentiamo il cognome, l'età, la città di nascita, tutti i numeri di telefono, il titolo del corso che insegnano, di quelli che hanno insegnato nel passato e di quelli che possono insegnare. I docenti possono essere dipendenti interni della società di formazione o collaboratori esterni. |
Dai requisiti a E-R
- se ha proprietà significative e descrive oggetti con esistenza autonoma
- entità
- se è semplice e non ha proprietà
- attributo
- se correla due o più concetti
- relazione
- se è caso particolare di un altro
- generalizzazione
Design Patterns
soluzioni progettuali a problemi comuni
largamente usati nell’ingegneria del software
Design Patterns: Elements of Reusable Object-Oriented Software (1997)
Reificazione di attributo di entità
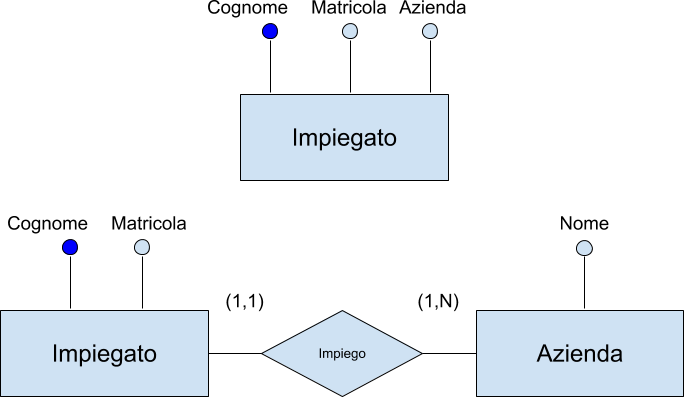
Part-of
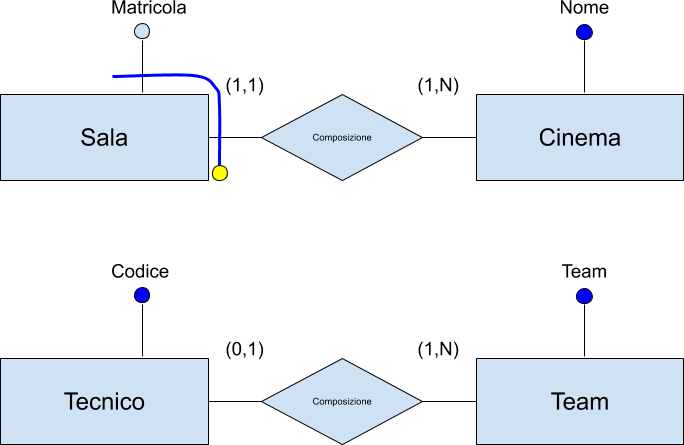
Instance-of
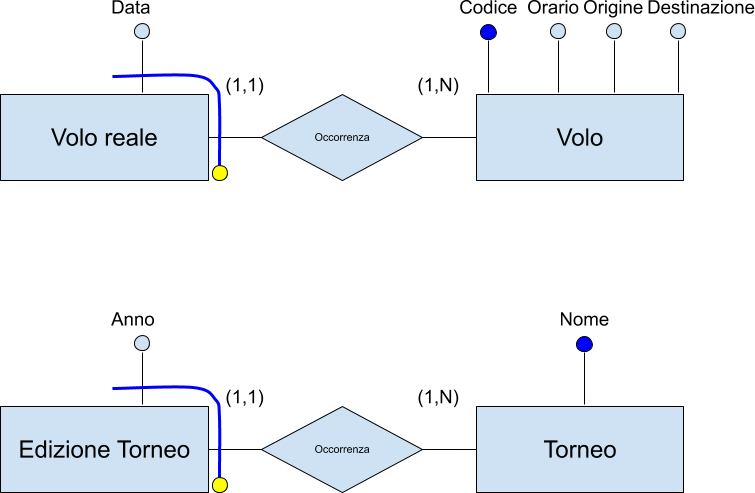
Progettazione Logica
Obiettivo
- trasformare lo schema concettuale in uno schema logico che rappresenti gli stessi dati
- non è una semplice traduzione!
Ingresso
- schema concettuale
- informazioni sul carico
Uscita
- schema logico
- documentazione associata
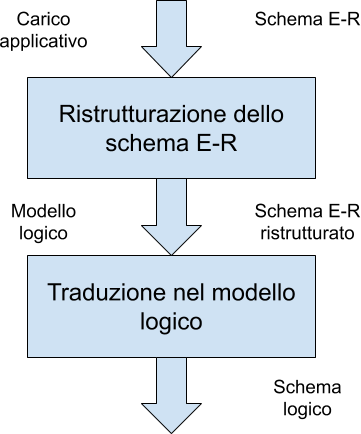
Ristrutturazione schema E-R
Motivazioni
- semplificare la traduzione
- le prestazioni non sono valutabili con precisione su uno schema concettuale
Ristrutturazione schema E-R
Osservazione
- uno schema E-R ristrutturato non è più uno schema concettuale nel senso stretto del termine
Ristrutturazione schema E-R
Indicatori delle prestazioni
- spazio: numero di istanze previste
- tempo: numero di istanze (di entità e relationship) visitate durante un’operazione
Ristrutturazione schema E-R
Caratteristiche delle operazioni
- tipo: interattiva o batch
- frequenza: numero medio di esecuzione in un certo periodo
Tavola dei volumi
| Concetto | Tipo | Volume |
|---|---|---|
| Sede | E | 10 |
| Dipartimento | E | 80 |
| Impiegato | E | 2000 |
| Progetto | E | 500 |
| Composizione | R | 80 |
| Afferenza | R | 1900 |
| Direzione | R | 80 |
| Partecipazione | R | 6000 |
Valutazione del costo
Supponiamo che le operazioni di interesse siano:
- Assegna un impiegato ad un progetto.
- Trova tutti i dati di un impiegato, del dipartimento nel quale lavora e dei progetti ai quali partecipa
- Trova i dati di tutti gli impiegati di un certo dipartimento
- Per ogni sede, trova i suoi dipartimenti con il cognome del direttore e l’elenco degli impiegati del dipartimento
Valutazione del costo
Operazione: trova tutti i dati di un impiegato, del dipartimento nel quale lavora e dei progetti ai quali partecipa
| Operazione | Tipo | Frequenza |
|---|---|---|
| Assegna impiegato a progetto | Interattiva | 50/giorno |
| Trova tutti i dati di un impiegato | Interattiva | 100/giorno |
| Trova dati di tutti impiegati in un dipartimento | Interattiva | 10/giorno |
| Trova dipartimenti in sedi | Batch | 2/settimana |
Attività della ristrutturazione
- analisi delle ridondanze
- eliminazione delle generalizzazioni
- partizionamento/accorpamento di entità e relationship
- scelta degli identificatori primari
Analisi delle ridondanze
Una ridondanza in uno schema E-R è un’informazione significativa ma derivabile da altre
In questa fase si decide se eliminare le ridondanze o mantenerle
Analisi delle ridondanze
Vantaggi delle ridondanze
- semplificazione delle interrogazioni
Svantaggi
- appesantimento degli aggiornamenti
- maggiore occupazione di spazio
Forme di ridondanza
Attributi derivabili
- da altri attributi della stessa entità (o relazione)
- da attributi di altre entità (o relazioni)
Relazioni derivabili dalla composizione di altre relazioni in presenza di cicli
Attributo derivabile

Attributo derivabile da altre entità
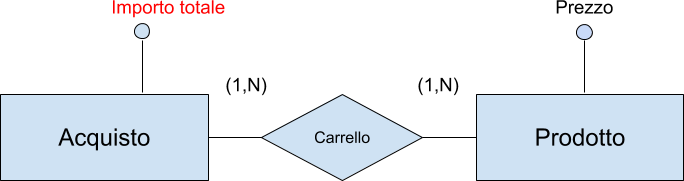
Ridondanza dovuta a ciclo
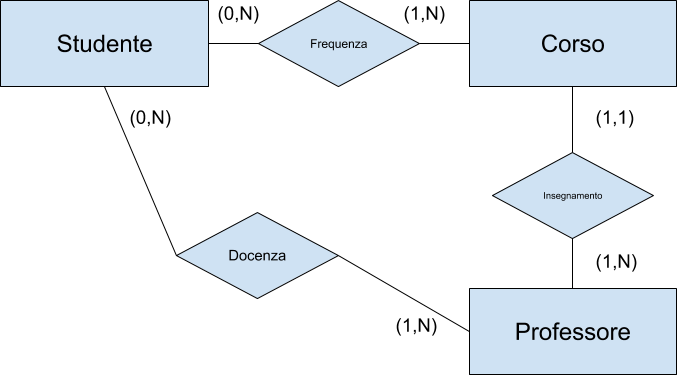
Analisi di una ridondanza
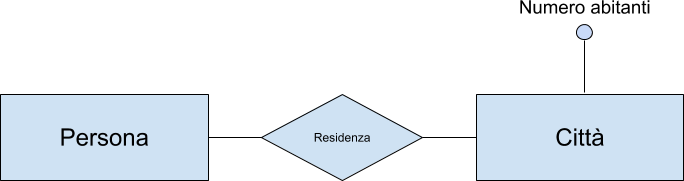
Analisi di una ridondanza
| Concetto | Tipo | Volume |
|---|---|---|
| Città | E | 200 |
| Persona | E | 1000000 |
| Residenza | R | 1000000 |
- Operazione 1: memorizza una nuova persona con la relativa città di residenza (500 volte al giorno)
- Operazione 2: stampa tutti i dati di una città (incluso il numero di abitanti) (2 volte al giorno)
Presenza di ridondanza
Operazione 1
| Concetto | Costrutto | Accessi | Tipo |
|---|---|---|---|
| Persona | Entità | 1 | S |
| Residenza | Relazione | 1 | S |
| Città | Entità | 1 | L |
| Città | Entità | 1 | S |
Operazione 2
| Concetto | Costrutto | Accessi | Tipo |
|---|---|---|---|
| Città | Entità | 1 | L |
Assenza di ridondanza
Operazione 1
| Concetto | Costrutto | Accessi | Tipo |
|---|---|---|---|
| Persona | Entità | 1 | S |
| Residenza | Relazione | 1 | S |
Operazione 2
| Concetto | Costrutto | Accessi | Tipo |
|---|---|---|---|
| Città | Entità | 1 | L |
| Residenza | Relazione | 5000 | L |
Conviene o no?
Presenza di ridondanza
- Operazione 1: 1500 accessi in scrittura e 500 in lettura al giorno
- Operazione 2: trascurabile (2 letture al giorno)
- Contiamo doppi gli accessi in scrittura
- Totale di 3500 accessi al giorno
Conviene o no?
Assenza di ridondanza
- Operazione 1: 1000 accessi in scrittura
- Operazione 2: 10000 accessi in lettura al giorno
- Contiamo doppi gli accessi in scrittura
- Totale di 12000 accessi al giorno
Eliminazione delle generalizzazioni
- il modello relazionale non può rappresentare direttamente le generalizzazioni
- entità e relazioni sono invece direttamente rappresentabili
- si eliminano perciò le generalizzazioni, sostituendole con entità e relazioni
Eliminazione delle generalizzazioni
Tre possibilità
- accorpamento dei figli nel genitore
- accorpamento del genitore nei figli
- sostituzione della generalizzazione con relazioni
Esempio
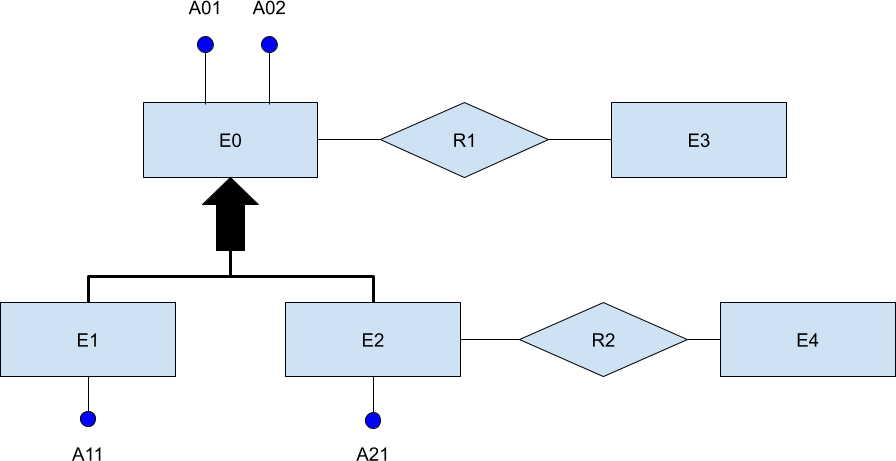
Accorpamento nel genitore
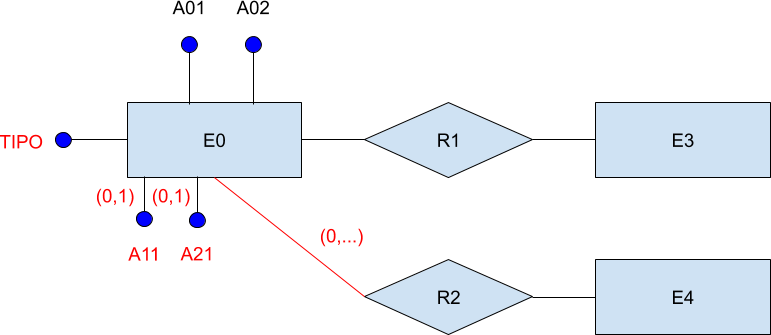
Accorpamento nei figli
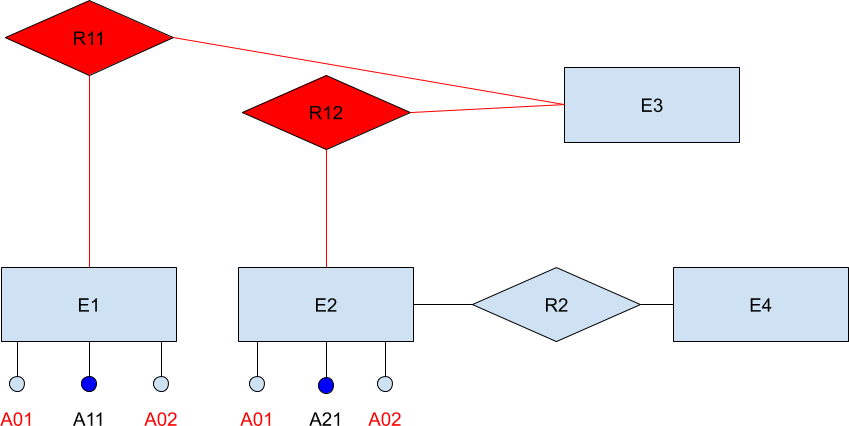
Inserimento di relazioni
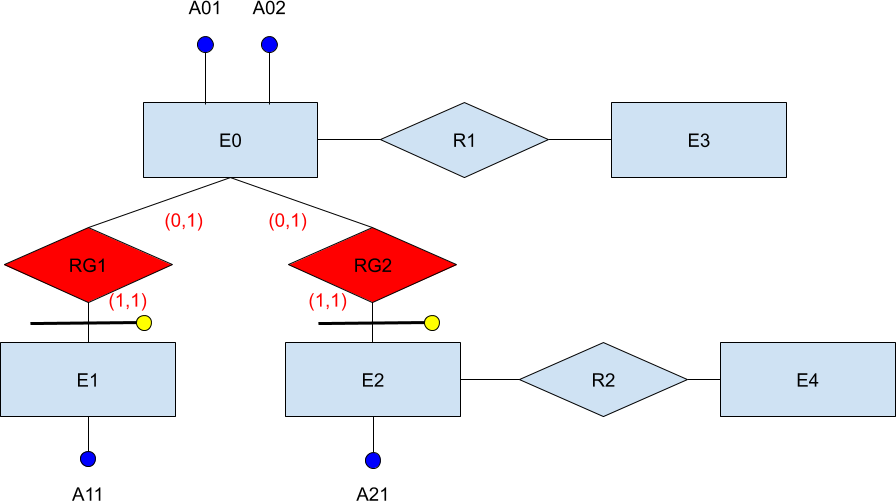
Cosa scegliere?
Accorpamento nel genitore
Conviene se gli accessi al padre e ai figli sono contestuali
Accorpamento ai figli
Conviene se gli accessi ai figli sono distinti
Inserimento di relazioni
Conviene se gli accessi alle entità figlie sono separati dagli accessi al padre
Sono anche possibili soluzioni ibride
Soluzione Ibrida
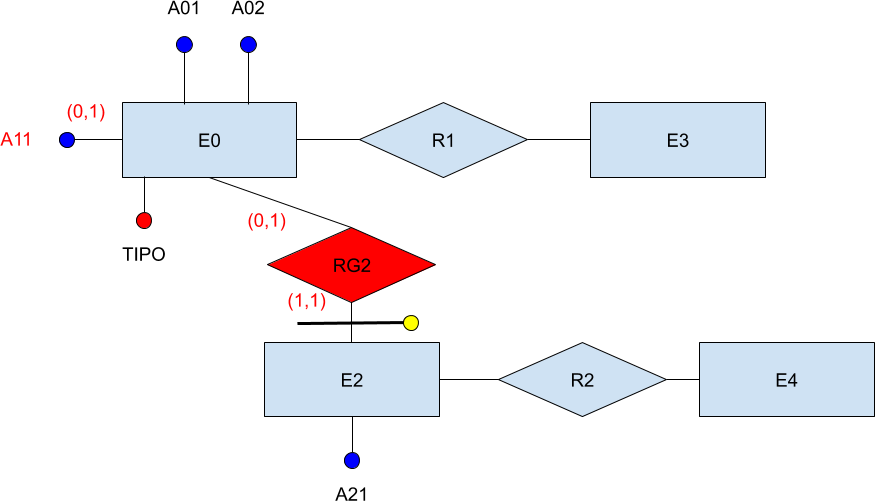
Partizionamento o accorpamento
Ristrutturazioni effettuate per rendere più efficienti le operazioni
Gli accessi si riducono:
- separando attributi di un concetto che vengono acceduti separatamente
- raggruppando attributi di concetti diversi, acceduti assieme
Casi principali di partizionamento
- partizionamento verticale di entità
- eliminazione di attributi multivalore
- partizionamento orizzontale di relationship
- accorpamento di entità/relationship
Partizionamento di entità
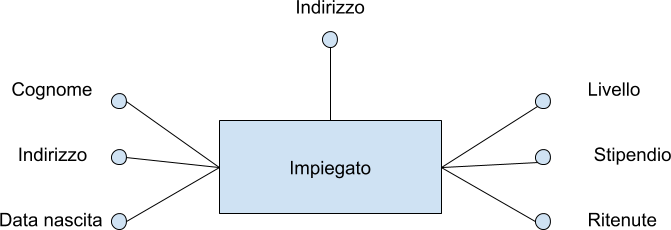
Partizionamento di entità
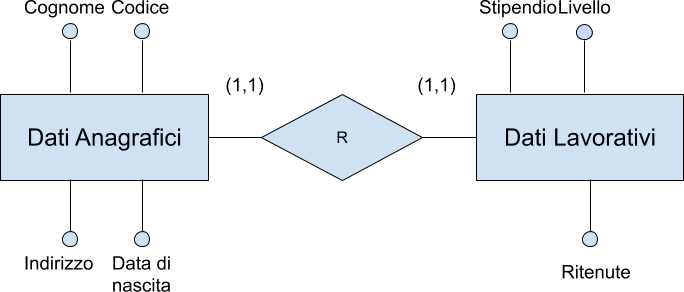
Eliminazione attributi multivalore
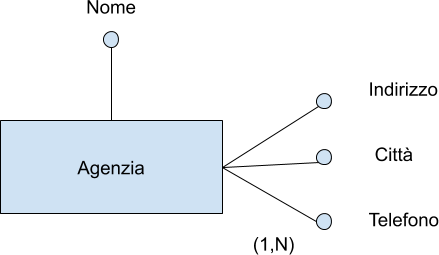
Eliminazione attributi multivalore
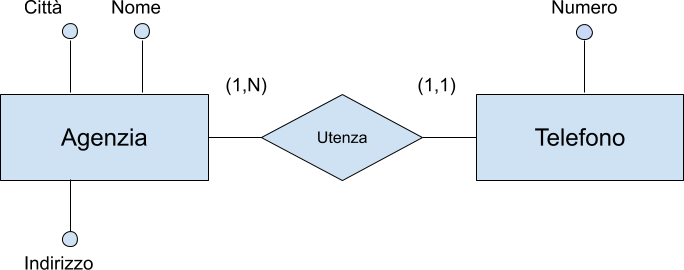
Accorpamento di entità
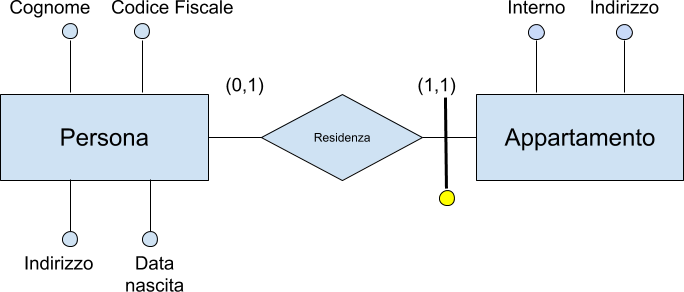
Accorpamento di entità
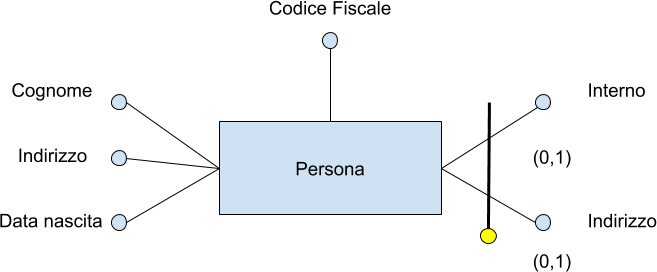
Partizionamento di associazione
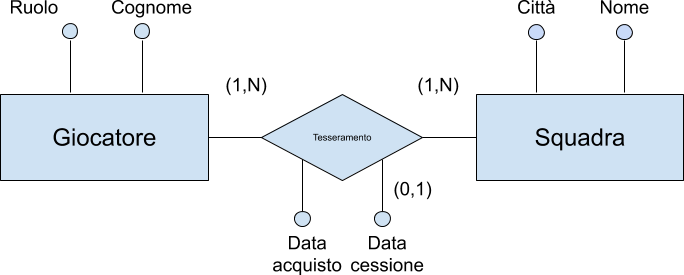
Partizionamento di associazione
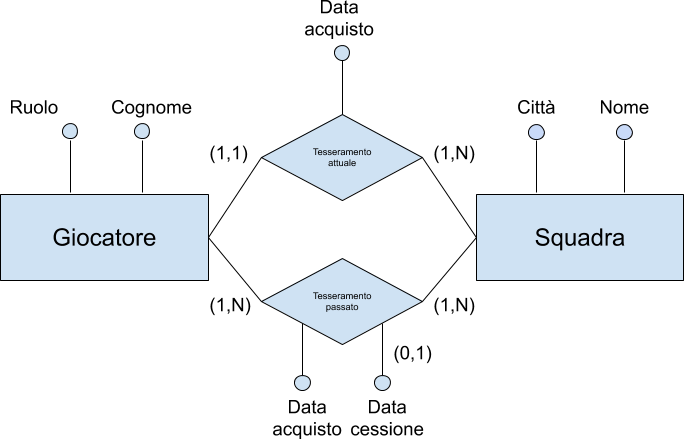
Scelta degli identificatori primari
Operazione indispensabile per la traduzione nel modello relazionale
Criteri:
- assenza di opzionalità
- semplicità
- utilizzo nelle operazioni più frequenti o importanti
Scelta degli identificatori primari
E se nessuno degli identificatori soddisfa i requisiti visti?
- si introducono nuovi attributi (codici) contenenti valori speciali generati proprio per questo scopo
Verso il modello relazionale
Idea di base
- le entità diventano relazioni sugli stessi attributi
- le associazioni (ovvero le relazioni ER) diventano relazioni sugli identificatori delle entità coinvolte (più gli attributi propri)
Relationship molti a molti
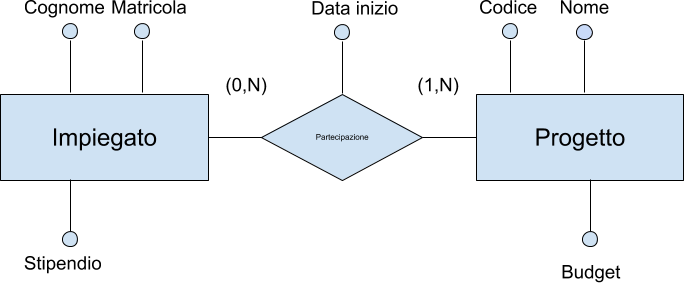
Impiegato(Matricola, Cognome, Stipendio)
Progetto(Codice, Nome, Budget)
Partecipazione(Matricola, Codice, DataInizio)
Nomi espressivi
Impiegato(Matricola, Cognome, Stipendio)
Progetto(Codice, Nome, Budget)
Partecipazione(Matricola, Codice, DataInizio)
Impiegato(Matricola, Cognome, Stipendio)
Progetto(Codice, Nome, Budget)
Partecipazione(Impiegato, Progetto, DataInizio)
Relationship ricorsive
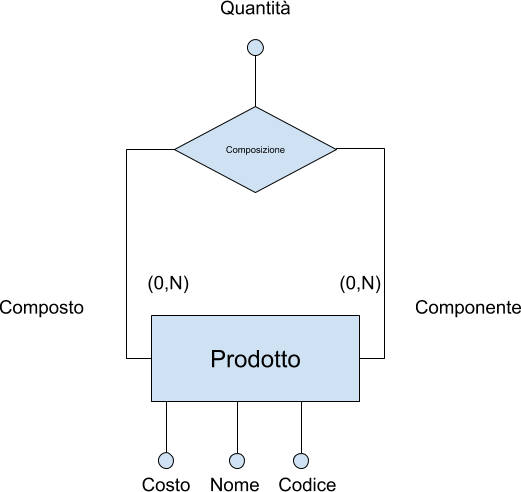
Prodotto(Codice, Nome, Costo)
Composizione(Composto, Componente, Quantità)
Relationship n-arie
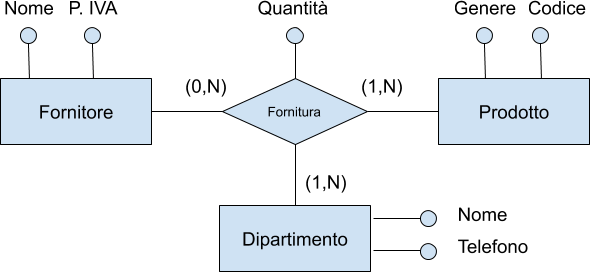
Fornitore(PartitaIVA, Nome)
Prodotto(Codice, Genere)
Dipartimento(Nome, Telefono)
Fornitura(Fornitore, Prodotto, Dipartimento, Quantità)
Relationship uno a molti
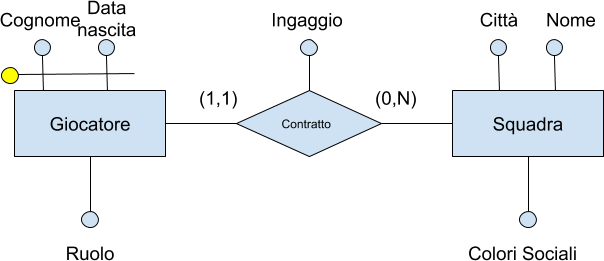
Giocatore(Cognome, DataNascita, Ruolo)
Contratto(CognomeGiocatore, DataNascitaGiocatore, Squadra, Ingaggio)
Squadra(Nome, Città, ColoriSociali)
È corretto?
Soluzione più compatta
Giocatore(Cognome, DataNascita, Ruolo)
Contratto(CognomeGiocatore, DataNascitaGiocatore, Squadra, Ingaggio)
Squadra(Nome, Città, ColoriSociali)
Giocatore(Cognome, DataNascita, Ruolo, Ingaggio, Squadra)
Squadra(Nome, Città, ColoriSociali)
- con vincolo di integrità referenziale fra Squadra in Giocatore e la chiave di Squadra
- se la cardinalità minima della relationship è 0, allora Squadra in Giocatore deve ammettere valore nullo
Relationship uno a molti
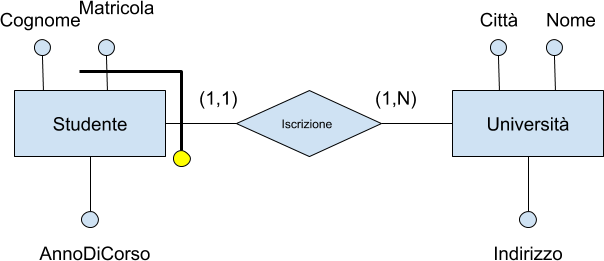
Studente(Matricola, Università, Cognome, AnnoDiCorso)
Università(Nome, Città, Indirizzo)
Relationship uno a uno
varie possibilità:
- fondere da una parte o dall'altra
- fondere tutto?
Relationship uno a uno
Impiegato(Codice, Cognome, Stipendio)
Dipartimento(Nome, Sede, Telefono, Direttore, DataInizio)
→ con vincolo di integrità referenziale, senza valori nulli
Schema finale
Impiegato(Codice, Cognome, Dipartimento, Sede, Data)
Dipartimento(Nome, Città, Telefono, Direttore)
Sede(Città, Via, CAP)
Progetto(Nome, Budget)
Partecipazione(Impiegato, Progetto)
Progettazione fisica
Progettazione fisica
Fase finale del processo di progettazione di una base di dati
- input:
- lo schema logico e le informazioni sul carico
- output:
- schema fisico, costituito dalle definizione delle relazioni con le relative strutture fisiche (e molti parametri, spesso legati allo specifico DBMS)
Memoria Principale e Secondaria
- I programmi possono fare riferimento solo a dati in memoria principale
- Le basi di dati debbono essere in memoria secondaria per due motivi:
- dimensioni
- persistenza
- I dati in memoria secondaria possono essere utilizzati solo se prima trasferiti in memoria principale
Accesso alla memoria secondaria
- tempo di posizionamento della testina (seek time): in media 2-15ms (a seconda del tipo di disco)
- tempo di latenza (rotational delay): 2-6ms (velocità di rotazione 4-15K giri al minuto)
- tempo di trasferimento di un blocco: frazioni di ms (velocità di trasferimento, 100-300MB al secondo)
in media non meno di qualche ms
SSD
Possiamo migliorare prestazioni usando SSD
- Costo: dipende
- SLC - veloce ma costoso (1 bit per cella)
- MLC - economico, ma più lento (2 bit per cella)
- Lettura rapida
- Scrittura: abbastanza rapida
- Cancellazione: problema…
- posso scrivere blocchi di 4Kb
- devo cancellare blocchi di 256Kb
DataBuffering
Presente nei DBMS degni di questo nome
- dati recenti o molto usati vengono salvati in memoria
- utile per velocizzare la lettura dei dati
- total access time = $A \times H_r + B \times (1- H_r)$
- $A$ = access time memoria primaria
- $B$ = access time memoria secondaria
- $H_r$ = buffer hit ratio
Indice
Indea fondamentale: indice analitico di un libro
Lista di coppie (termine, pagina) ordinata alfabeticamente sui termini, posta in fondo al libro e separabile da esso
Indice di file
- struttura ausiliaria per l’accesso (efficiente) ai record di un file
- si basa sui valori di un campo detto “pseudochiave”
Un indice $I$ di un file $F$ è un altro file con record a due campi: chiave e indirizzo, ordinato secondo i valori della chiave
Tipi di indici
Indice primario
Indice su un campo sul cui ordinamento è basata la memorizzazione
Esempio: indice generale di un libro
Tipi di indici
Indice secondario
Indice su un campo con ordinamento diverso da quello di memorizzazione
Esempio: indice analitico di un libro
Tipi di indici
- i benefici legati agli indici secondari sono molto più sensibili
- ogni file può avere al più un indice primario e un numero qualunque di indici secondari (su campi diversi)
- esempio: una guida turistica può avere l’indice dei luoghi e quello degli artisti
Occorre davvero un indice per tutto?
Tipi di indice
Indice denso
Contiene tutti i valori della chiave
Indice sparso
Contiene solo alcuni valori della chiave
- un indice primario di solito è sparso
- un indice secondario deve essere denso
- ci sono (in generale) più record per un valore della pseudochiave
Esempio
| Indice primario | |
|---|---|
| Matricola | Dove |
| 001 | 0x22200 |
| 004 | 0x222AA |
| 006 | 0x2223B |
| Dati | |
|---|---|
| Matricola | Nome |
| 001 | Giorgio |
| 002 | Franco |
| 003 | Alberto |
| 004 | Paolo |
| 005 | William |
| 006 | Andrea |
| 007 | Filippo |
| 008 | Marco |
| Indice secondario | |
|---|---|
| Nome | Dove |
| Alberto | 0x2231 |
| Andrea | 0x2223B |
| Filippo | 0x2731 |
| Franco | 0x2831 |
| Giorgio | 0x22200 |
| Marco | 0x3231 |
| Paolo | 0x222AA |
| William | 0x2201 |
Caratteristiche degli indici
- accesso diretto efficiente, sia puntuale sia per intervalli
- scansione sequenziale ordinata efficiente
- modifiche della chiave, inserimenti, eliminazioni inefficienti
Strutture fisiche nei DBMS relazionali
Struttura primaria
- disordinata (heap, “unclustered”) → più usata
- ordinata (“sequential”), anche su una pseudochiave
- hash (“clustered”), anche su una pseudochiave, senza ordinamento: l’hash della chiave determina la posizione del record sul disco
- clustering di più relazioni
Strutture fisiche nei DBMS relazionali
Indici (densi/sparsi, semplici/composti)
- ISAM (statico), di solito su struttura ordinata
- B-tree (dinamico)
- Hash (secondario, poco dinamico)
B-tree
- struttura ad albero
- le foglie sono i puntatori ai dati
- molto efficiente
- usato per
=, >, >=, <, <=oBETWEEN

Fonte: wikipedia

Fonte: wikipedia
HASH
- bucket: unità di storage che contiene uno o più valori
- la funzione di hashing permette di ottenere il bucket (possibili valori diversi stesso bucket)
- overflow: bucket pieno
- funziona solo per ricerche
=o<> - estremamente veloce
Progettazione fisica nel modello relazionale
- La caratteristica comune dei DBMS relazionali è la disponibilità degli indici
- la progettazione fisica spesso coincide con la scelta degli indici (oltre ai parametri strettamente dipendenti dal DBMS)
- Le chiavi (primarie) delle relazioni sono di solito coinvolte in selezioni e join: molti sistemi prevedono (oppure suggeriscono) di definire indici sulle chiavi primarie
Progettazione fisica nel modello relazionale
- Se le prestazioni sono insoddisfacenti, si tara il sistema aggiungendo o eliminando indici
- Verificare se e come gli indici sono utilizzati con il comando SQL show plan oppure explain
Normalizzazione
Normalizzazione
- Normalizzazione è il processo di semplificazione di un data base per ottenere la struttura ottimale
- Forme Normali sono progressioni lineari di regole da applicare al data base, con ciascuna forma normale si ottiene un miglioramento del data base
Forme normali
- Una forma normale è una proprietà di una base di dati relazionale che ne garantisce la qualità, cioè l’assenza di determinati difetti
- Quando una relazione non è normalizzata:
- presenta ridondanze,
- si presta a comportamenti poco desiderabili durante gli aggiornamenti
- Le forme normali sono di solito definite sul modello relazionale, ma hanno senso in altri contesti, ad esempio il modello E-R
| Impiegato | Stipendio | Progetto | Bilancio | Funzione |
|---|---|---|---|---|
| Rossi | 20 | Marte | 2 | tecnico |
| Verdi | 35 | Giove | 15 | progettista |
| Verdi | 35 | Venere | 15 | progettista |
| Neri | 55 | Venere | 15 | direttore |
| Neri | 55 | Giove | 15 | consulente |
| Neri | 55 | Marte | 2 | consulente |
| Mori | 48 | Marte | 2 | direttore |
| Mori | 48 | Vedere | 15 | progettista |
| Bianchi | 48 | Vedere | 15 | progettista |
| Bianchi | 48 | Giove | 15 | direttore |
Anomalie
- lo stipendio di ciascun impiegato è ripetuto in tutte le ennuple relative (ridondanza)
- se lo stipendio di un impiegato varia, è necessario andarne a modificare il valore in diverse ennuple (anomalia di aggiornamento)
- Se un impiegato interrompe la partecipazione a tutti i progetti, dobbiamo cancellarlo (anomalia di cancellazione)
- Un nuovo impiegato senza progetto non può essere inserito (anomalia di inserimento)
Dove abbiamo sbagliato?
Abbiamo usato un’unica relazione per rappresentare informazioni eterogenee
- gli impiegati con i relativi stipendi
- i progetti con i relativi bilanci
- le partecipazioni ai progetti con le relative funzioni
Prima forma normale
La prima forma normale (1NF) dice che tutte le colonne devono essere atomiche
- una colonna per valore
- non ci sono unità ripetitive
Prima forma normale
| ID | Cognome | Nome | Telefoni |
|---|---|---|---|
| 321 | De Lorenzo | Andrea | 555-55555; 5551-55111 |
| ID | Cognome | Nome | Telefono1 | Telefono2 |
|---|---|---|---|---|
| 321 | De Lorenzo | Andrea | 555-55555 | 5551-55111 |
| ID | Cognome | Nome |
|---|---|---|
| 321 | De Lorenzo | Andrea |
| Persona | Telefono |
|---|---|
| 321 | 555-55555 |
| 321 | 5551-55111 |
Seconda forma normale
Una tabella è in seconda forma normale (2NF) se è in 1NF e ciascuna colonna dipende (in senso stretto) dalla PK
- tabelle devono memorizzare solo dati relativi ad una sola entità descritta dalla PK
- 2NF viene ottenuta spezzando tabelle in parti normalizzate che descrivano una singola entità
- questa fase è detta decomposizione
Seconda forma normale
| Matricola | Esame | Studente | Voto |
|---|---|---|---|
| 1234 | M01 | De Lorenzo | 28 |
| 1234 | M03 | De Lorenzo | 30 |
| 1234 | I12 | De Lorenzo | 25 |
| Matricola | Esame | Voto |
|---|---|---|
| 1234 | M01 | 28 |
| 1234 | M03 | 30 |
| 1234 | I12 | 25 |
| Matricola | Studente |
|---|---|
| 1234 | De Lorenzo |
Terza forma normale
Una tabella è in terza forma normale (3NF) se è in 2NF e se ogni attributo dipende solo dalla PK
- tutte le colonne sono indipendenti tra loro
- creare tabelle di lookup
- non ci sono colonne calcolate
Terza forma normale
| Torneo | Anno | Vincitore | Data di nascita vincitore |
|---|---|---|---|
| Indiana Invitational | 1998 | Al Fredrickson | 21 luglio 1975 |
| Cleveland Open | 1999 | Bob Albterson | 28 settembre 1968 |
| Des Moines Masters | 1999 | Al Fredrickson | 21 luglio 1975 |
| Torneo | Anno | Vincitore |
|---|---|---|
| Indiana Invitational | 1998 | Al Fredrickson |
| Cleveland Open | 1999 | Bob Albterson |
| Des Moines Masters | 1999 | Al Fredrickson |
| Vincitore | Data di nascita vincitore |
|---|---|
| Al Fredrickson | 21 luglio 1975 |
| Bob Albterson | 28 settembre 1968 |
Normalizzare
- 1NF: una colonna un valore, rimuovere gruppi ripetuti
- 2NF: spezzare in tabelle che descrivano entità separate, spezzare le PK composte
- 3NF: rimuovere colonne calcolate e creare eventualmente tabelle di lookup
Quando denormalizzare
- Performance
- Esempi tipici: rinuncia alla 3NF, campi calcolati, statistiche, …
- Farlo deliberatamente
- Avere una ottima regione per farlo
- Essere ben consci di cosa questo comporti in termini di performance
- Documentare la decisione
Approccio pratico
- Analisi dell’applicazione
- Scrittura obiettivi fondamentali su carta
- Bozza dei data entry su carta
- Creazione di un diagramma E/R
- Considera reports esistenti (o creane di nuovi su carta)
Approccio pratico
- Modifica schema concettuale in funzione dei reports
- Semplificazione dello schema concettuale – progettazione logica – schema delle tabelle
- Su carta, aggiungi records, usando dati reali.
- Incomincia la normalizzazione. Crea PK su ciascuna tabella. Assicurati che la PK prevenga possibili duplicazioni.
Approccio pratico
- Su carta, annota le chiavi esterne, aggiungendole se necessario alle tabelle. Stabilisci le relazioni tra le tabelle specificando se sono 1-1 o…
- Se si tratta di relazioni molti a molti progetta le tabelle di sponda (linking table) e valuta se utilizzare chiavi composte su queste tabelle.
- 1NF? Tutti i campi sono atomici? Ci sono gruppi che si ripetono?
Approccio pratico
- 2NF? Ciascuna tabella descrive una singola entità? Ciascuna PK delle singole tabelle implica tutte le altre colonne. Se sono presenti chiavi primarie composte, spezza le chiavi.
- 3NF? Ci sono colonne calcolate? Ci sono colonne dipendenti? Eliminale con delle tabelle di lookup.
- Aggiusta le relazioni tra le tabelle eventualmente denormalizza il data base solo dove risulta necessario.
- Crea tabelle e relazioni nel programma scelto (Oracle? MySql? Sql Server?)
Approccio pratico
- Crea il prototipo delle queries, forms e reports. Potrebbero in questa fase evidenziarsi problemi nel progetto. Aggiusta il progetto.
- Mostra il prototipo al cliente.
- Torna al progetto ed aggiungi Business Rules
- Crea le forms e report finali. Sviluppa l’applicazione.
- Consegna al cliente per il test. Modifica il progetto di conseguenza
- Consegna finale
NoSQL
Problema
Applicazione desktop che accede ad un RDBMS
- probabilmente pochi utenti (1000?)
- probabilmente pochi accessi contemporanei
Problema
Estendiamo l’applicazione per gestire un web-store
- gli utenti diventano tanti
- le query saturano la macchina
- non funziona più!
Soluzioni
- comprare un server migliore
- master/slave
- vertical partitioning
- horizontal partitioning
Master/Slave
- replico i dati su più macchine
- solo il master può fare modifiche
- ho tanti slave per le interrogazioni
Vertical Partitioning
- una entità su più tabelle
- esempio: sposto l’indirizzo dalla tabella Cliente
Horizontal Partitioning
- anche detto sharding
- replico lo schema su più macchine
- salvo le tuple su istanze diverse (shared key)
Sembra facile…
Gli RDBMS non sono fatti per essere distribuiti
- come facciamo le join?
- come si fanno gli update?
- lo fa il motore o l’applicazione?
Big Data
Termine per indicare un insieme di dati talmente ampio che i metodi tradizionali di persistenza e processo sono inadeguati
Strutture Nidificate
| Da Filippo Via Roma 2, Roma | ||
| Ricevuta Fiscale 1235 del 12/01/2020 | ||
| 3 | Coperti | 3,00 |
| 2 | Antipasti | 6,20 |
| 3 | Primi | 12,00 |
| 2 | Bistecche | 18,00 |
| - | ||
| - | ||
| Totale | 39,20 | |
| Da Filippo Via Roma 2, Roma | ||
| Ricevuta Fiscale 1240 del 13/10/2020 | ||
| 2 | Coperti | 2,00 |
| 2 | Antipasti | 7,00 |
| 2 | Primi | 8,00 |
| 2 | Orate | 20,00 |
| 2 | Caffè | 2,00 |
| - | ||
| Totale | 39,00 | |
Scomposto in più tabelle
Abbiamo ristrutturato il documento dividendolo in tabelle diverse
| Ricevute | ||
|---|---|---|
| Numero | Data | Totale |
| 1235 | 12/10/2020 | 39,20 |
| 1240 | 12/10/2020 | 39,00 |
| Dettaglio | ||||
|---|---|---|---|---|
| Numero | Riga | Qtà | Descrizione | Importo |
| 1235 | 1 | 3 | Coperti | 3,00 |
| 1235 | 2 | 2 | Antipasti | 6,20 |
| 1235 | 3 | 3 | Primi | 12,00 |
| 1235 | 4 | 2 | Bistecche | 18,00 |
| 1240 | 1 | 2 | Coperti | 2,00 |
| ... | ... | ... | ... | ... |
NoSQL
Not Only SQL
- di solito non richiedono uno schema fisso
- non usano il concetto di join
NO TABELLE
NOSQL vs RDBMS
- “ascia e martello”: scopi diversi, uno non sostituisce l’altro
- gestione “big data”
- assenza di schema predefinito
- più facili da amministrare
- scala orizzontale (scale-out)
Scala orizzontale
Scala verticale
- miglioro l’hardware della macchina
- sfruttato da RDBMS
Scala orizzontale
- aumento il numero di macchine
- NoSQL DBMS gestiscono più facilmente
Teorema di Brewer (CAP)
Consistency
scrivo un valore, lo leggo ed ottengo lo stesso dato
Availability
posso leggere/scrivere i dati
Partitions
il sistema può sopravvivere a perdite di dati
se ne possono scegliere al massimo due!
BASE
ALternativa al paradigma ACID
- Basically Available
- Soft state
- Eventually consistent
BASE
Basically available
sembra che il sistema funzioni sempre
SOft state
il sistema non sarà sempre consistente
Eventually consistent
prima o poi il sistema diventerà consistente
Modalità NoSQL
- Key-value (Amazon Dynamo)
- Column-based (Apache Cassandra)
- Document-based (MongoDB)
- Graph-based (Neo4j)
Key-value
- una sola tabella
- coppie chiave-valore (dizionario)
- molto utilizzati per fare ricerche
- es: sistema di messaggistica, chiave = utente, valore = messaggio
Document
- simili a key-value, ma con contenuti complessi
- posso ottenere porzioni del contenuto
tipicamente salvati in JSON
{'id': 1001, 'customer_id': 7231, 'products': [ {'product_id':4432, 'quantity': 9}, {'product_id':4422, 'quantity': 19} ] }
Column-based
- dati salvati per colonna
- colonne contengono dati simili
Dati aggregati
modello basato su aggregazione
- dati collegati tra di loro vengono salvati assieme
- più facile distribuire
- più veloci ricerche
Svantaggi
- ottenere dati aggregati: facile
- devo creare nuove associazioni? complesso
- aggregazioni diverse? meglio RDBMS
Grafi
- nodi e archi per rappresentare dati
- molto comodi per descrivere “relazioni” complesse
- richiedono linguaggio proprio per interrogare
Aggregazione e transazione
- ACID: dobbiamo mettere tutto in una transazione
- transazioni rallentano
- leggere e modificare andrebbe tutto in una transazione
- con modello aggregato non ho questo problema
- introduco numeri di versione
MongoDB
- modello orientato ai documenti
- replicazione asincrona
- auto-sharding
- MapReduce
MongoDB
Modello dai
- oggetti JSON raggruppati in collezioni
- senza schema
- JSON standard: null, boolean, integer, string, double, array e object
- altri tipi: date, object id, binary data, regular expression e code
Collezione di utenti
// utente admin
{
name : "admin",
password : "P4ssword",
groups : [ "administrators" , "system" ],
email : "admin@units.it"
}
// utente pippo
{
name : "pippo",
openId : "http://pippo.blogspot.com",
groups : [ "users" ],
birthdate : new Date(1984, 2, 12),
email : "pippo@gmail.com"
}
// utente user
{
name : "user",
password : "passwordsicura",
score : 31,
email : "info@gmail.com"
}
Associazione tra documenti
campo sender con valore uguale a name
{
sent : new Date(2010, 3, 5),
text : "Ciao a tutti, ..."
sender : "admin",
views : 120
}
{
sent : new Date(2010, 3, 6),
text : "Argomento a caso, ...",
sender : "user"
views : 300,
tags : [ "Java" ]
}
Associazione tra documenti
documenti innestati
{
name : "user1",
address : {
zipCode : "60100",
country : "Italy"
},
messages : {
{
sent : new Date(2010, 3, 5),
text : "Ciao a tutti, ...",
views : 120
},
{
sent : new Date(2010, 3, 18),
text : "Articolo MokaByte, ...",
views : 300,
tags : [ "Java" ]
}
}
}
MongoDB - Indicizzazione
- ogni oggetto ha una proprietà
_id - su
_idviene aggiunto un indice automaticamente posso aggiungere indici su qualsiasi proprietà o oggetto
db.users.ensureIndex( {name : 1} )db.users.ensureIndex( { name : 1, address : 1 } )
MongoDB - Indici sparsi
- potrebbe non esistere una certa proprietà
se voglio indicizzarla uso indice sparso
db.users.ensureIndex( { openId : 1 } , { sparse : true } );
MongoDB - Replicazione
- master/slave (meno automatizzato)
- insiemi di replicazione
Insiemi di replicazione
- vengono raggruppati vari nodi assieme
- ogni nodo elegge autonomamente un master
- se il master è indisponibile, ne viene scelto un altro
MongoDB - auto-sharding
MOngoDB scala orizzontalmente
- shard nodi che contengono i dati in base alla shard key
- server di configurazione nodo con i metadati
- router nodi a cui si collegano i client e propagano richieste
MongoDB - auto-sharding
- avviamo almeno due nodi shard (opzione
--shardsvr) - avviamo un server di configurazione (opzione
--configsvr) - avviare un server router
- configurare il cluster
MongoDB - auto-sharding
configurazione del cluster
registrare gli shard
db.runCommand( { addshard : "shardhost" } )
frammentazione collezioni
db.runCommand( { enablesharding : "mydatabase" } )
registrare gli shard
db.runCommand( {
shardcollection : "mydatabase.users",
key : {name : 1} } )
MongoDB - shell
Interfaccia per inviare comandi
- basata su linguaggio JavaScript
programma separato che si collega al DBMS
use nome_del_db db.nome_del_db
MongoDB - Gestione dati
Inserimento
db.users.save( {
name : "pippo",
groups : [ "users", "writers" ],
birthdate : new Date(1985, 2, 3) }
)
db.users.save( {
name : "admin",
groups : [ "administrators" ],
system : true }
)
MongoDB - Ricerca
Tutti gli elementi di una collezioni
db.users.find()
Tutti gli elementi con un certo pattern
db.users.find( { system: true } )
MongoDB - Ricerca
Condizione OR
db.users.find({ $or : [
{groups : "administrators"},
{system : {$exists : false}}
]
})
Subset attributi
db.users.find( { system : true } ,
{ name : 1 } )
MongoDB - Update
Conoscendo l’ID
db.users.save( { _id : ObjectId("4d7d4621473a000000006598"),
name : "admin", groups : [ "administrators" , "system" ] }
Tramite ricerca
db.users.update({ name : "admin" },
{ name : "admin", groups : [ "administrators" , "system" ] }
)
MongoDB - Cancellazione
Tutta la collezione
db.users.remove()
Tramite ricerca
db.users.remove( { name : "pippo" } )
MapReduce
- operazione utilizzata in ambito BigData
- si compone di due parti: Map e Reduce
- Map: filtra e ordina i dati
- Reduce: esegue la funzione di aggregazione
MapReduce
Voglio contare quante volte compaiono parole in tutti i documenti
- Map: trova la parole, per ogni parola “emette” una chiave ed un valore
- Reduce: aggrega le varie chiavi (parole) e conta quante sono
MapReduce - Esempio
function map(String name, String document):
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
sum = 0
for each pc in partialCounts:
sum += pc
emit (word, sum)

Fonte: mongoDB Documentation
MapReduce - MongoDB
Contare i tag
{ message : "testo del messaggio", tags : [ "Java", "MongoDB", "SQL" ] }
{ message : "altro test", tags : [ "SQL" ] }
MapReduce - MongoDB
Contare i tag
Map
function mapTags() {
this.tags.forEach(function(t) {
emit(t, 1);
});
}
Reduce
function totalValues(key, values) {
var total = 0;
for ( var i=0; i < values.length; i++)
total += values[i];
return total;
}
MapReduce - MongoDB
mrRes = db.messages.mapReduce(mapTags, totalValues)
{
"result" : "tmp.mr.mapreduce_1300279574_6",
"timeMillis" : 5,
"counts" : {
"input" : 2,
"emit" : 4,
"output" : 3
},
"ok" : 1,
}
MapReduce - MongoDB
db.find(mrRes.results)
{ "_id" : "Java", "value" : 1 }
{ "_id" : "MongoDB", "value" : 1 }
{ "_id" : "SQL", "value" : 2 }
MongoDB
Connessione
MongoDB raggruppa i documenti per collezioni
MongoClient mongo = new MongoClient( "localhost");
DB db = mongo.getDB( "mydb" );
DBCollection coll = db.getCollection("impiegati");
MongoDB
Nuovo documento
DBCollection coll = db.getCollection("impiegati");
BasicDBObject doc = new BasicDBObject("name", "Pip")
.append("type", "dirigente")
.append("count", 1)
.append("info", new BasicDBObject("tel","04055555")
.append("email", "test@email.it"));
coll.insert(doc);
MongoDB
Query
BasicDBObject q = new BasicDBObject("name", "Pip");
cursor = coll.find(q);
try {
while(cursor.hasNext()) {
System.out.println(cursor.next());
}
} finally {
cursor.close();
}
MongoDB
Query con parametro
// i > 50
query = new BasicDBObject("i",
new BasicDBObject("$gt", 50));
cursor = coll.find(q);
try {
while(cursor.hasNext()) {
System.out.println(cursor.next());
}
} finally {
cursor.close();
}
MongoDB
Query con parametro
// name == "pippo" || name == "pluto"
BasicDBList or = new BasicDBList();
or.add("pippo");
or.add("pluto");
query = new BasicDBObject("$or",
new BasicDBObject("name",or));
cursor = coll.find(q);
try {
while(cursor.hasNext()) {
System.out.println(cursor.next());
}
} finally {
cursor.close();
}
Conviene
Facebook search
MySQL > 50 GB
- Writes Average : ~300 ms
- Reads Average : ~350 ms
Cassandra > 50 GB
- Writes Average : 0.12 ms
- Reads Average : 15 ms
XML
eXtensible Markup Language
Markup Language
- Markup deriva dall’industria della stampa
- istruzioni di stili dettagliati per tipografie
- normalmente scritte a mano sulle copie (es: sottolineature di testo che deve essere settato in italico)
- markup languages: fanno lo stesso per documenti computerizzati
Markup language
- aggiungono una struttura logica ad un documento, o indicano come debba essere il layout (su carta o su video)
- set di istruzioni che si prestano ad un processo automatico
Markup Language
Di solito è una sequenza di caratteri in un file testo che indica una struttura oppure un comportamento del contenuto
- HTML
- RTF
- $\LaTeX$
- Markdown
HTML
<TITLE>This is the title.</TITLE>
This is <B>bold</B> and this is <I>italic</I>
RTF
{\rtf
Ciao!\par
Ecco del testo in {\b grassetto}.\par
}
$\LaTeX$
Una formula $\frac{x^2}{2}$
Una formula $\frac{x^2}{2}$
Markdown
## Queste slide
sono *fatte* in **markdonw**
Queste slide
sono fatte in markdonw
XML
- elementi racchiusi tra coppie di TAG
- ogni elemento può contenerne altri
- definizione arbitraria di elementi
- Document Type Definition
- contenuto e rappresentazione grafica separati
XML Basics
- un documento XML è composto da elements:
<tag>content</tag> - ogni documento XML ha un elemento di partenza (root element)
- ogni elemento può contenere informazioni addizionali descritte dai suoi attributes:
<tag name="value"></tag>
XML - Gerarchia
<persona>
<nome>Andrea</nome>
<indirizzo>
<via>Via Belposto</via>
<civico>18</civico>
<citta>Disneyland</citta>
</indirizzo>
</persona>
Dettagli
Nel documento posso inserire anche altri dettagli
- Commenti
<!-- commento --> - dichiarazioni XML
<?xml version="1.0" encoding="UTF-8"?> - schema, DTD, …
Validazione XML
Well Formed XML
Un documento è Well Formed se ha una sintassi XML corretta
Valid XML
Un documento è Valid XML se è well formed e risulta conforme allre regole DTD o XML Schema Definition (XSD)
Document Type Definition
- XML non specifica un set di tag
- come faccio a sapere se il mio documento è corretto? Cosa si aspetta chi lo riceverà?
- DTD definisce la struttura dei documenti con una lista di elementi legali
- Internal DOCTYPE declaration
- External DOCTYPE declaration
Internal DTD
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE note
[ <!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
<note>
<to>Jo</to>
<from>Mary</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend</body>
</note>
External DTD
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Jo</to>
<from>Mary</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend</body>
</note>
<!DOCTYPE note
[ <!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
XML Schema Definition
- file XSD
- analogo a DTD, ma redatto in XML
XSD
Definisce:
- elementi che possono essere usati nel documento
- attributi contenuti nel documento
- quali elementi sono child elements
- l’ordine dei child elements
- il numero di child objects
- se un elemento è vuoto o può includere del testo
- data types per elementi ed attributi
- valori di default e valori fissati per elementi ed attributi
XML Schema Definition
XML Schema Definition
Mr. Walter C. Brown
49
Featherstone Street
LONDON
EC1Y 8SY
UK
XSD o DTD?
- XSD sono estendibili per future estensioni
- XSD sono scritti in XML
- XSD supportano data types
- XSD supportano namespaces
Reverse engineering
- esistono dei tool di conversione:
- input → file XSD
- output → classi in {Java, C#}
- perché mi serve?
- i linguaggi moderni hanno tool di serializzazione/deserializzazione per XML
- molti sistemi comunicano tramite XML (Es: web services SOAP)
- xsd.exe nel mondo C#
- xjc nel mondo java
Da XSD a Java
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "", propOrder = {"recipient","house","street","town",
"county", "postCode", "country"})
@XmlRootElement(name = "Address")
public class Address {
@XmlElement(name = "Recipient", required = true)
protected String recipient;
@XmlElement(name = "House", required = true)
protected String house;
@XmlElement(name = "Street", required = true)
protected String street;
@XmlElement(name = "Town", required = true)
protected String town;
@XmlElement(name = "County")
protected String county;
@XmlElement(name = "PostCode", required = true)
protected String postCode;
@XmlElement(name = "Country")
protected String country;
}
Fogli di stile
- rappresentazione grafica
- due possibilità
| CSS | XML | |
|---|---|---|
| Può essere usato con HTML? | ✓ | X |
| Può essere usato con XML? | ✓ | ✓ |
| Transformation language? | X | ✓ |
| Sintassi | CSS | XML |
CSS
CATALOG
{background-color: #ffffff; width: 100%;}
CD
{display: block; margin-bottom: 30pt; margin-left: 0;}
TITLE
{color: #FF0000; font-size: 20pt;}
ARTIST
{color: #0000FF; font-size: 20pt;}
COUNTRY,PRICE,YEAR,COMPANY
{Display: block; color: #000000; margin-left: 20pt;}
XML Schema Definition
Empire Burlesque
Bob Dylan
USA Columbia
10.90
1985
XSL – Più che uno Style Sheet
- XPath: un linguaggio per definire parti di un documento XML
- XQuery: un linguaggio che permette di estrarre porzioni di un documento
- XSLT: un linguaggio per trasformare documenti XML
XPath
Consente la scrittura di path in un documento con lo scopo di selezionare parti di documenti XML
.nodo corrente..nodo padre del nodo corrente/nodo radice, o figlio del nodo corrente//discendente del nodo corrente@attributo del nodo corrente*qualsiasi nodo
XPath - Esempio
document(“libri.xml”)/Elenco/Libro
- document(nome) ottiene la radice
- restituisce l’insieme di tutti i libri contenuti nell’elenco che si trovano nel documento libri.xml
XQuery
Linguaggio di programmazione per interrogare Data Base XML
for $x in doc("books.xml")/bookstore/book
where $x/price>30
order by $x/title
return $x/title
XSL Transformation
Trasforma un documento XML in un altro documento XML o altro tipo di documento (HTML, ecc.)
<persons>
<person username="JS1">
<name>John</name>
<family-name>Smith</family-name>
</person>
<person username="MI1">
<name>Morka</name>
<family-name>Ismincius</family-name>
</person>
</persons>
XSLT: Esempio
John
Morka
Parsing di XML
- tree-based
- event-based
Parsing Tree-based
- carico tutto l’XML in memoria
- ok per documenti piccoli
- rappresentazione DOM
Parsing Event-based
- accedo un nodo alla volta
- interagisco in tempo reale
- un po’ scomodo, ma ok per grossi documenti
Esercizio: agenzia immobiliare
L'agenzia immobiliare gestisce delle transazioni di vendita e di affitto di immobili, che hanno un codice una data ed un valore. In caso di affitto, ci interessa il periodo. Ogni agenzia ha un identificativo, un nome ed una città in cui si trova.
Gli immobili hanno un codice, un indirizzo, una città, il numero di locali e la metratura. Alcuni sono di interesse storico e di questi è importante l'anno di costruzione. Altri sono ristrutturati e ci interessa la data di ultima ristrutturazione.
Gli immobili possono essere acquistati da enti, che sono o persone o società. Degli enti ci va salvato il codice fiscale, l'indirizzo, la città e la regione. Delle persone ci interessa nome e cognome, mentre delle aziende il nome e il capitale sociale.
Esercizio: agenzia immobiliare
- I comuni chiedono le transazioni dell'ultimo anno che coinvolgono vendite effettuate da persone (10 volte al giorno)
- I comuni chiedono le transazioni dell'ultimo anno che coinvolgono affitti ottenuti da aziende (10 volte al giorno)
- Gli uffici amministrativi chiedono la situazione delle transazioni dell'ultimo mese, con data ultima ristrutturazione (se esiste) e anno di costruzione (se noto) (1 volta al giorno)
- Si richiede la situazione degli immobili ristrutturati, con data ultima ristrutturazione (1 volta l'anno)
Schema Concettuale
Schema Logico